Ŀ¼
MySQL����MySQL�ʺ��ڷֲ�ʽ���㻷���ĸ�ʵ�á�������汾����������NDB�ش洢���棬������1���������ж��MySQL����������MySQL 5.1�����ư汾�С��Լ������µ�Linux�汾���ݵ�RPM���ṩ�˸ô洢���档��ע�⣬Ҫ����MySQL�صĹ��ܣ����밲װmysql-server��mysql-max RPM����
Ŀǰ�ܹ�����MySQL�صIJ���ϵͳ��Linux��Mac OS X��Solaris����һЩ�û�ͨ���ɹ�����FreeBSD��������MySQL�أ���MySQL AB��˾��δ��ʽ֧�ָ����ԣ�����������Ŭ�����Ա�ʹMySQL����������MySQL֧�ֵ����в���ϵͳ�ϣ�����Windows�����ҵ�֧���µ�ƽ̨ʱ�������¸�ҳ�档
���½��������ڽ��еĹ����������ݽ�����MySQL�صIJ����ݻ����仯������MySQL�صĸ�����Ϣ�������MySQL AB��˾����վhttp://www.mysql.com/products/cluster/��
������Ҳϣ��ʹ��MySQL AB�ṩ�����ֶ�����Դ��
�� MySQL���ʼ��б���
�� MySQL�û���̳�ϵ�����������
���ڴص�һЩ�������⣬��μ�17.10�ڣ���MySQL�س������������������MySQL�ص����֣����Ķ��ҷ�������Ա�����������Ϊ��������������MySQL�����������������
MySQL����һ�ּ������ü���������������ϵͳ�в����ڴ��С����ݿ�Ĵء�ͨ��������ϵ�ṹ��ϵͳ�ܹ�ʹ�����۵�Ӳ�������Ҷ���Ӳ��������Ҫ���⣬����ÿ��������Լ����ڴ�ʹ��̣������ڵ�����ϡ�
MySQL�ؽ�����MySQL����������ΪNDB�ġ��ڴ��С���ʽ�洢���漯���������������ǵ��ĵ��У�����NDBָ������洢������ص����ò��֣������MySQL����ָ����MySQL��NDB�洢�������ϡ�
MySQL����һ���������ɣ�ÿ̨������Ͼ������Ŷ��ֽ��̣�����MySQL��������NDB�ص����ݽڵ㣬�������������Լ������ܣ�ר�ŵ����ݷ��ʳ����ڴ�����Щ����Ĺ�ϵ����μ���ͼ��
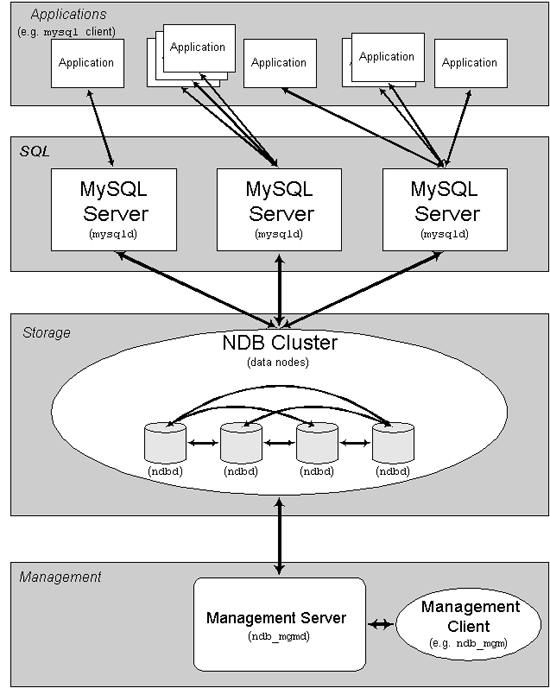
������Щ����һ����MySQL�ء������ݱ��浽NDB�ش洢������ʱ���������������ݽڵ��ڡ��ܹ��Ӵ�����������MySQL������ֱ�ӷ�����Щ������ˣ��ڽ����ݱ����ڴ��ڵĹ��ʱ�Ӧ�ó����У����ijһӦ�ó��������1λ��Ա�Ĺ��ʣ����в�ѯ�����ݵ�����MySQL�����������̷������ֱ仯��
����MySQL�أ����������ݽڵ��ڵ����ݿɱ�ӳ�䣬���ܹ������������ݽڵ�Ĺ��ϣ�������������������״̬��ʧ���������⣬�����������Ӱ�졣����������Ӧ�ó����ܹ���������ʧ�����ˣ��������������Դ��
ͨ����MySQL�����뿪��Դ�����磬MySQLΪ������Ҫ������Ա�ṩ�˾��и߿����ԡ������ܺͿ������ԵĴ����ݹ�����
NDB��һ�֡��ڴ��С��洢���棬�����п����Ըߺ�����һ���Ժõ��ص㡣
�ܹ�ʹ�ö��ֹ����л�����ƽ��ѡ������NDB�洢���棬���Դز����ϵĴ洢���濪ʼ���MySQL�ص�NDB�洢����������������ݼ�����ȡ���ڴر����ڵ��������ݡ�
���棬���ǽ�����������NDB�洢�����һЩMySQL���������ɵ�MySQL�ص����÷�����
Ŀǰ��MySQL�صĴز��ֿɶ�����MySQL�������������á���MySQL���У��ص�ÿ�����ֱ���Ϊ1���ڵ㡣
ע�ͣ��ںܶ�����£�����ڵ㡱����ָ���������������MySQL��ʱ������ʾ���ǽ��̡��ڵ�̨������Ͽ�����������Ŀ�Ľڵ㣬Ϊ�ˣ����Dz���������������
������ؽڵ㣬����͵�MySQL�������У������������ڵ㣬������ڵ�ֱ��ǣ�
�� ����(MGM)�ڵ㣺����ڵ�������ǹ���MySQL���ڵ������ڵ㣬���ṩ�������ݡ�������ֹͣ�ڵ㡢���б��ݵȡ���������ڵ㸺����������ڵ�����ã�Ӧ�����������ڵ�֮ǰ������������ڵ㡣MGM�ڵ���������ndb_mgmd�����ġ�
�� ���ݽڵ㣺����ڵ����ڱ���ص����ݡ����ݽڵ����Ŀ�븱������Ŀ��أ���Ƭ�εı��������磬��������������ÿ������������Ƭ�Σ���ô����4�����ݽڵ㡣û�б�Ҫ��һ�����ϵĸ��������ݽڵ���������ndbd�����ġ�
�� SQL�ڵ㣺�����������ʴ����ݵĽڵ㡣����MySQL�أ��ͻ��˽ڵ���ʹ��NDB�ش洢����Ĵ�ͳMySQL����������������£�SQL�ڵ���ʹ������mysqld �Cndbcluster�����ģ���ndbcluster���ӵ�my.cnf��ʹ��mysqld������
�����ð����Դ��е����ڵ�����ã��Լ����ýڵ�֮��ĵ���ͨ����·������Ŀǰ��Ƶ�MySQL�أ�����ͼ���ڣ��Ӵ��������������ڴ�ռ�ʹ����������洢�ڵ���ͬ�ʵģ����⣬Ϊ���ṩ��һ�����õ㣬��Ϊ���壬�ص������������ݾ�λ��1�������ļ��С�
����������(MGM�ڵ�)��������������ļ��ʹ���־�����е�ÿ���ڵ�ӹ��������������������ݣ�������ȷ����������������λ�õķ�ʽ�������ݽڵ��ڳ�����Ȥ���¼�ʱ���ڵ㽫���������¼�����Ϣ���䵽������������Ȼ��������Ϣд�����־��
���⣬������������Ŀ�Ĵؿͻ��˽��̻�Ӧ�ó������Ƿ�Ϊ�������ͣ�
�� ��MySQL�ͻ��ˣ�����MySQL�أ���������ģ��Ǵ��ࣩMySQLû�����𡣻��仰�����ܹ�����PHP��Perl��C��C++��Java��Python��Ruby�ȱ�д������MySQLӦ�ó������MySQL�ء�
�� �����ͻ���������ͻ�����������������������ṩ�����ŵ�������ֹͣ�ڵ㡢������ֹͣ��Ϣ���٣����Ե��汾������ʾ�ڵ�汾��״̬��������ֹͣ���ݵȵ����
���ڽ�������ι滮����װ�����ú�����MySQL�صĻ���֪ʶ����17.4�ڣ���MySQL�ص����á��и�����ʾ����ͬ������������ܵIJ����ָ�ϣ����õĽ��Ӧ�����õ�MySQL�أ�����������ݿ����ԺͰ�ȫ���������Ҫ��
�ڱ����У����ǽ������������ݣ�Ӳ��������Ҫ���������ˣ�MySQL�صİ�װ���������ˣ��ص�������ֹͣ�������������������ݿ⣬�Լ�ִ�в�ѯ�ķ�����
�����ٶ�
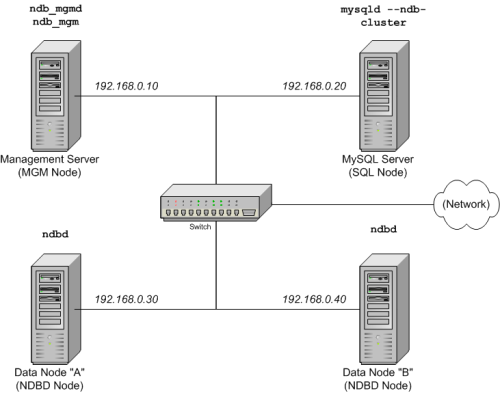
�����������¼ٶ���
1. ���ǽ���������4���ڵ�Ĵأ�ÿ���ڵ�λ�ڲ�ͬ�������ϣ������ڵ��͵���̫���о��й̶��������ַ������������
|
�ڵ� |
IP��ַ |
|
����(MGM)�ڵ� |
192.168.0.10 |
|
MySQL������(SQL)�ڵ� |
192.168.0.20 |
|
����(NDBD)�ڵ�"A" |
192.168.0.30 |
|
����(NDBD)�ڵ�"B" |
192.168.0.40 |
2. ͨ����ͼ�ɸ�����ı�����㣺
4. ע�ͣ����ڼ��ԣ��Լ��ɿ��ԣ�����Ŀ��ǣ��ڱ�����֪ʶ���������ǽ�ʹ����ֵIP��ַ�����ǣ��������������о߱�DNS�������ܣ������ôصĹ����У���ʹ������������IP��ַ����Ϊ��ѡ��ʽ��Ҳ��ʹ��/etc/hosts�ļ��������ṩ������ѯ�IJ���ϵͳ�ĵ�Ч�������õĻ�����
5. �����ǵij����У�ÿ̨�������ǻ���Intel������PC��PC�����е��dz�����һ����Linux�汾������ϵͳ�Ա����ð�װ�ڴ����ϣ�δ�����κβ���Ҫ�ķ��߱���TCP/IP�����ͻ��˵ĺ��IJ���ϵͳӦ���Է������ǵ�Ҫ���⣬Ϊ�˼��ԣ����ǻ��ٶ����������ϵ��ļ�ϵͳ�ǵ�ͬ�ġ������Щ�����ϵ��ļ�ϵͳ��ͬ���������Щ˵������Ӧ�ĵ�����
6. ��ÿ̨�����ϰ�װ�˱���100 Mbps��1��������̫������Ϊÿ��������װ��ǡ�������������ñ�����̫������װ�ã��罻�����ȣ���4̨�����������������л���Ӧʹ�þ�����ͬ������������Ҳ����˵�����е�����4̨����Ӧȫ��ʹ��100M��������ȫ��ʹ��1G��������MySQL�ؽ�������100 Mbps�����У�����������̫�����ṩ���õ����ܡ�
ע�⣬MySQL�ز��ʺ�����ͨ�Ե���100 Mbps�����硣���ڸ�ԭ�������ǣ����ڹ���������Internet������MySQL�غ��ѳɹ���Ҳ���Ƽ���������
7. �����������ݣ����ǽ�ʹ���������ݿ⣬�����ݿ�ɴ�MySQL AB��˾����վ�����ء����ڸ����ݿ�ռ�õĿռ���Խ�С�����Ǽٶ�ÿ̨������256 MB RAM�����������в���ϵͳ������NDB���̡��Լ��洢���ݿ⣨�������ݽڵ㣩��
�����ڱ����������в��õ���Linux����ϵͳ���������������˵���Ͳ�����˵���������ģ�Ҳ��������Solaris��Mac OS X�����⣬���ǻ��ٶ����������˰�װ�����þ߱��������ܵIJ���ϵͳ�Ļ���֪ʶ�����ܹ�����Ҫ��ʱ���ð�����
��һ�ڣ����Ǹ���ϸ��������MySQL�ص�Ӳ��������������Ҫ����μ�17.3.1�ڣ���Ӳ��������������������
MySQL�ص�һ��ǿ���ŵ����ڣ�������������ͨӲ���ϣ�������Ҫ�ϴ��RAM���������û������Ҫ��������Ϊʵ�ʵ����ݴ洢�������ڴ��н��еġ���ע�⣬δ������ı䣬���Ǵ�����δ����MySQL�ذ汾��ʵ�ֻ��ڴ��̵Ĵ洢������Ȼ�����CPU�����CPU����ǿ���ܡ����ڴؽ�����˵�����ڴ��Ҫ����Խ��١�
�ص�����Ҫ��̶����С���������ϵͳ����Ҫ�κ�����ģ�顢����Ӧ�ó������þ���֧��MySQL�ء�����Mac OS X��Solaris������װ�����㹻������Linux�����ġ�������������װӦ�������ȫ����MySQL����Ҫ��ܼ�MySQL-max 5.1����������������ȫ����Ҫ���ô�֧�֣�����ʹ��MySQL��-max�汾�������Լ�����MySQL����ʹ�ôء��ڱ����У����Ǽٶ���ʹ������Linux����Ӧ��-max�����ư汾������Solaris��Mac OS X����ϵͳ����Ӧ�IJ��ֿ�ͨ��MySQL��������ҳ���ã�http://dev.mysql.com/downloads/��
���ڽڵ�֮���ͨ�ţ���֧�ֲ��ñ����˷�����TCP/IP����������ÿ̨������Ԥ�����Ҫ����1�����100 Mbps��̫������������Ϊ����Ĵأ�������Ͻ����������缯������·�������ṩ������ͨ�ԡ�����ǿ�ҽ��飬Ӧ�����Լ�������������MySQL�أ�����Ǵػ���������������ԭ�����£�
�� ��ȫ�ԣ��ؽڵ�֮���ͨ��δ�����κ�������ܻ��������MySQL���ڴ����Ψһ���������ǣ����ܱ��������������дء�������㽫MySQL������WebӦ�ã���Ӧ��ȷ��λ�ڷ���ǽ���棬���Ҳ�Ӧλ������ķǾ�������DMZ���������ط���
�� Ч�ʣ���ר�еĻ��ܱ���������������MySQL�أ��������ؾ��ܶ���������֮��Ĵ�����ΪMySQL��ʹ�õ����Ľ����������ܷ�ֹ�Դ����ݵķǷ����ʣ����һ���ȷ���ؽڵ㲻�����������������֮����Ϣ����ĸ��š�Ϊ����ǿ�ɿ��ԣ�����ʹ��˫��������˫�����Է�ֹ������ֵ�����ϣ���������ͨ����·���ܶ��豸������֧�ֹ����л����ܡ�
Ҳ����MySQL��һ��ʹ�ø���SCI����ģ����չ�ļ�����ӿڣ������ⲻ��Ҫ��ġ����ڸ�Э��ĸ�����Ϣ���Լ�����MySQL�ص��÷�����μ�17.7�ڣ���ʹ����MySQL�صĸ��ٻ���������ÿ̨���д洢��SQL�ڵ��MySQL����������������������ϰ�װMySQL-max�����ư汾�����ڹ����ڵ㣬û�б�Ҫ��װMySQL�����������ư汾����Ӧ��װMGM�������˿ڼල����Ϳͻ��˶����ư汾���ֱ���ndb_mgmd��ndb_mgm�����ڱ����У����ǽ�����Ϊÿ�ִؽڵ㰲װ��ȷ�Ķ����ư汾����IJ��衣
MySQL AB�ṩ��Ԥ����Ķ������ļ�������֧�ִأ��㲻��Ҫ�Լ�������Щ�ļ��������ȷʵ��Ҫ���ƵĶ������ļ�����μ�2.8.3�ڣ����ӿ���Դ������װ��������ˣ�����ÿ̨����������װ���̵ĵ�һ���Ǵ�MySQL�����������ļ�mysql-max-5.1.2-alpha-pc-linux-gnu-i686.tar.gz�����Ǽٶ��㽫���ļ����ڸ�������/var/tmpĿ¼�¡�
����32λ��64λLinuxƽ̨��������Ӧ��RPM��RPM��װ��-max�������ļ�֧��NDB�ش洢���档�����ѡ��ʹ�����Ƕ����Ƕ������ļ�����������дؽڵ�����л����ϰ�װ-server��-max������������ʹ��RPM��װMySQL�ĸ�����Ϣ����μ�2.4�ڣ�����Linux�°�װMySQL������ʹ��RPM��ɰ�װ������Դؽ������ã���μ�17.3.3�ڣ������á���
ע�ͣ���ɰ�װ�������κζ������ļ������������нڵ�����ǽ��������ִ����������ķ�����
�洢�ڵ��SQL�ڵ㰲װ
�����Ϊ���д洢�ڵ��SQL�ڵ����̨������ÿһ̨�ϣ���ϵͳ���û�����ִ���������裺
1. ������/etc/passwd��/etc/group�ļ�����ʹ�ò���ϵͳ�ṩ�����ڹ����û�����Ĺ��ߣ����鿴��ϵͳ���Ƿ��Ѵ���mysql����mysql�û���������ΪijЩ����ϵͳ�Ὣ����Ϊ��װ���̵�һ�������Դ�����������Dz����ڣ������µ�mysql�û�����Ȼ��Ϊ��������1��mysql�û���
2. groupadd mysql
3. useradd -g mysql mysql
4. ������������ļ���Ŀ¼����������ļ�����������mysql-max��ִ���ļ���symlink��ע�⣬����MySQL�İ汾�ţ�ʵ�ʵ��ļ�����Ŀ¼����������ͬ��
5. cd /var/tmp
6. tar -xzvf -C /usr/local/bin mysql-max-5.1.2-alpha-pc-linux-gnu-i686.tar.gz
7. ln -s /usr/local/bin/mysql-max-5.1.2-alpha-pc-linux-gnu-i686 mysql
8. ����mysqlĿ¼���������ṩ�����ڴ���ϵͳ���ݿ�Ľű���
9. cd mysql
10. scripts/mysql_install_db --user=mysql
11.ΪMySQL������������Ŀ¼���ñ�Ҫ��Ȩ�ޣ�
12. chown -R root .
13. chown -R mysql data
14. chgrp -R mysql .
ע�⣬��ÿ̨�������ݽڵ�Ļ����ϣ�����Ŀ¼��/usr/local/mysql/data�����ù����ڵ�ʱ���õ�������Ϣ����μ�17.3.3�ڣ������á�����
15.��MySQL�����ű�������ǡ����Ŀ¼�£�ʹ֮��Ϊ��ִ�еĽű������������Ա�����������ϵͳʱ������
16. cp support-files/mysql.server /etc/rc.d/init.d/
17. chmod +x /etc/rc.d/init.d/mysql.server
18. chkconfig --add mysql.server
�ڴˣ�����ʹ��Red Hat��chkconfig�������������ű������ӣ�������IJ���ϵͳ��ʹ��ǡ�������ڸ�Ŀ�ĵķ�ʽ����Debian�ϵ�update-rc.d��
���ס�����ڴ洢�ڵ��SQL�ڵ����ڵ�ÿ̨����������ֱ�ָ���������衣
�����ڵ㰲װ
����MGM���������ڵ㣬����Ҫ��װmysqld��ִ���ļ������谲װ����MGM�������Ϳͻ��˵Ķ������ļ��������ļ��������ص�-max�������ҵ����ٴμٶ��㽫���ļ�������/var/tmpĿ¼�£�����ϵͳʱ��Ҳ����˵ʹ��sudo, su root��ϵͳ�ĵ�Ч����ٶ�����ϵͳ����Ա�˻���Ȩ�ޣ���ִ���������裬�ڴع����ڵ������ϰ�װndb_mgmd��ndb_mgm��
1. ����/var/tmpĿ¼���ӵ����ļ��н�ndb_mgm��ndb_mgmd��ȡ��ǡ����Ŀ¼�£���/usr/local/bin��
2. cd /var/tmp
3. tar -zxvf mysql-max-5.1.2-alpha-pc-linux-gnu-i686.tar.gz /usr/local/bin '*/bin/ndb_mgm*'
4. �������ļ����ڵ�Ŀ¼��Ȼ��ʹ�������ļ���Ϊ��ִ�еģ�
5. cd /usr/local/bin
6. chmod +x ndb_mgm*
��17.3.3�ڣ������á��У����ǽ�Ϊʾ�����е����нڵ㴴���ͱ�д�����ļ���
�������ǵ�4�ڵ㡢4����MySQL�أ���Ҫ��д4�������ļ���ÿ���ڵ�/����1����
�� ÿ�����ݽڵ��SQl�ڵ���Ҫ1��my.cnf�ļ������ļ��ṩ��������Ϣ��connectstring�������ַ�����������֪ͨ�ڵ㵽�����ҵ�MGM�ڵ㣻�Լ�һ�У�����֪ͨ���������������ݽڵ�Ļ������ϵ�MySQL������������NDBģʽ�¡�
���������ַ����ĸ�����Ϣ����μ�17.4.4.2�ڣ���MySQL�������ַ�������
�� �����ڵ���Ҫconfig.ini�ļ������ļ�֪ͨ�ڵ��ж�����Ҫά���ĸ�������Ҫ��ÿ�����ݽڵ���Ϊ���ݺ�������������ڴ棬���ݽڵ��λ�ã���ÿ�����ݽڵ��ϱ������ݵĴ���λ�ã��Լ�SQL�ڵ��λ�á�
���ô洢�ڵ��SQL�ڵ�
���ݽڵ������my.cnf�ļ��൱�������ļ�Ӧλ��/etcĿ¼�£��������κ��ı��༭�����б༭�����б�Ҫ���������ļ��������磺
vi /etc/my.cnf
���ڱ�ʾ���е�ÿ�����ݽڵ��SQL�ڵ㣬my.cnf�ļ������ڣ�
# Options for mysqld process:
[MYSQLD]
ndbcluster # run NDB engine
ndb-connectstring=192.168.0.10 # location of MGM node
# Options for ndbd process:
[MYSQL_CLUSTER]
ndb-connectstring=192.168.0.10 # location of MGM node
�����������ݺ����ļ����˳��ı��༭�������������ݽڵ㡰A�������ݽڵ㡰B����SQL�ڵ�Ļ����Ϸֱ�ִ������������
���ù����ڵ�
����MGM�ڵ�ĵ�һ���Ǵ���Ŀ¼����Ŀ¼���ڴ�������ļ���Ȼ�������ļ����������磨�Ը��û��������У���
mkdir /var/lib/mysql-cluster
cd /var/lib/mysql-cluster
vi config.ini
�ڴ�ʹ����vi�������ļ����������κ��ı��༭����Ӧ��ʤ�Ρ�
�������ǵĵ������ã�config.ini�ļ�Ӧ�����ڣ�
# Options affecting ndbd processes on all data nodes:
[NDBD DEFAULT]
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
# TCP/IP options:
[TCP DEFAULT]
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: It is recommended beginning with MySQL 5.0 that
# you do not specify the portnumber at all and simply allow
# the default value to be used instead
# Management process options:
[NDB_MGMD]
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
# Options for data node "A":
[NDBD]
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's datafiles
# Options for data node "B":
[NDBD]
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's datafiles
# SQL node options:
[MYSQLD]
hostname=192.168.0.20 # Hostname or IP address
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
��ע�ͣ�"world"���ݿ�ɴ�վ��http://dev.mysql.com/doc/���أ������ڡ�ʾ������Ŀ�£���
һ�����������е������ļ���ָ������Щ���ѡ��������أ�����֤���н��̾����������С������ⷽ������ۣ���μ�17.3.4�ڣ����״���������
���ڿ���MySQL�����ò����Լ����÷��ĸ�����Ϣ����μ�17.4.4�ڣ��������ļ�����17.4�ڣ���MySQL�ص����á�����������б����йص�MySQL�����ã���μ�17.6.5.4�ڣ����ر��ݵ����á���
ע�ͣ��ع����ڵ��Ĭ�϶˿���1186�����ݽڵ��Ĭ�϶˿�2202����MySQL 5.0.3��ʼ���������ѱ��ſ������ܹ����ݿ��еĶ˿��Զ���Ϊ���ݽڵ����˿ڡ�
������ú������ز��������ѡ����������ݽڵ����ڵ������Ϸֱ�����ÿ���ؽڵ���̡������ܹ����κ�˳�������ڵ㣬�����ǽ��飬Ӧ�������������ڵ㣬Ȼ�������洢�ڵ㣬�������SQL�ڵ㣺
1. �ڹ��������ϣ���ϵͳshell������������������MGM�ڵ���̣�
2. shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
ע�⣬�����á�-f������--config-file��ѡ�����ndb_mgmd�������ҵ������ļ���������μ�17.5.3�ڣ���ndb_mgmd�������������������̡�����
3. ��ÿ̨���ݽڵ������ϣ������״�����������������������NDBD���̣�
4. shell> ndbd --initial
ע�⣬��Ӧ���״�����ndbdʱ�����ڱ��ݣ��ָ������ñ仯������ndbdʱʹ�á�--initial�������������Ҫ��ԭ�����ڣ��ò�����ʹ�ڵ�ɾ��������ndbdʵ�������ġ����ڻָ����κ��ļ��������ָ�����־�ļ���
5. ���ʹ��RPM��SQL�ڵ����ڵĴ������ϰ�װ��MySQL���ܹ���ҲӦ����ʹ�ð�װ��/etc/init.d�µ������ű���SQL�ڵ�������MySQL���������̡�ע�⣬Ҫ�����С�-max���������������ļ������˱���RPM�⣬����Ҫ��װ-max������RPM��
���һ��˳����������ȷ�����˴أ���ô������Ӧ�����С�ͨ������ndb_mgm�����ڵ�ͻ��ˣ��ɶ�����в��ԡ������Ӧ�����ڣ�
shell> ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm> SHOW
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.30 (Version: 5.1.2-alpha, Nodegroup: 0, Master)
id=3 @192.168.0.40 (Version: 5.1.2-alpha, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.10 (Version: 5.1.2-alpha)
[mysqld(SQL)] 1 node(s)
id=4 (Version: 5.1.2-alpha)
�����������ݿ��ܻ����в�ͬ����ȡ��������ʹ�õ�MySQL�汾��
ע�ͣ����������ʹ�ý����MySQL�汾��������ῴ������Ϊ��[mysqld(API)]����SQL�ڵ㡣����һ�����ڵ��÷������ѷ�����
���ڣ�Ӧ����MySQL���д������ݿ⣬�������ݡ������ⷽ��ļ�Ҫ���ۣ���μ�17.3.5�ڣ�������ʾ�����ݲ�ִ�в�ѯ����
��û��ʹ�ôص�MySQL��ȣ���MySQL���ڲ������ݵķ�ʽû��̫�������ִ���������ʱӦ��ס���㣺
�� ��������ENGINE=NDB��ENGINE=NDBCLUSTERѡ���������ALTER TABLEѡ����ģ���ʹ��NDB�ش洢�����ڴ��ڸ������ǡ����ʹ��mysqldump��������������ݿ����������ı��༭���д�SQL�ű���������ѡ�����ӵ��κα�������䣬��������ѡ��֮һ�滻�κ����е�ENGINE����TYPE��ѡ����磬�ٶ�����һ��MySQL����������֧��MySQL�أ����������������ݿ⣬��������㵼�����б��Ķ��壺
�� shell> mysqldump --add-drop-table world City > city_table.sql
�����õ�city_table.sql�ļ��У�������������������䣨�Լ���������������INSERT��䣩��
DROP TABLE IF EXISTS City;
CREATE TABLE City (
ID int(11) NOT NULL auto_increment,
Name char(35) NOT NULL default '',
CountryCode char(3) NOT NULL default '',
District char(20) NOT NULL default '',
Population int(11) NOT NULL default '0',
PRIMARY KEY (ID)
) ENGINE=MyISAM;
INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800);
# (remaining INSERT statements omitted)
��Ҫȷ��MySQLΪ�ñ�ʹ����NDB�洢���档��������ɸ�����ķ���������һ�ַ����ǣ��ڽ�����������ݿ�֮ǰ�����䶨�壬ʹ�������ڣ���ʹ�á����С���Ϊʾ������
DROP TABLE IF EXISTS City;
CREATE TABLE City (
ID int(11) NOT NULL auto_increment,
Name char(35) NOT NULL default '',
CountryCode char(3) NOT NULL default '',
District char(20) NOT NULL default '',
Population int(11) NOT NULL default '0',
PRIMARY KEY (ID)
) ENGINE=NDBCLUSTER;
INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800);
# (etc.)
���ڽ���Ϊ�����ݿ���ɲ��ݵ�ÿ����������ҪΪ�䶨��ִ��������������ɸ������������ǣ�����world.sql�ļ���ִ��������-�滻��������ENGINE=NDBCLUSTER�滻���е�TYPE=MyISAMʵ��������㲻������ĸ��ļ���Ҳ��ʹ��ALTER TABLE��������μ�����Ľ��ܡ�
�ٶ������ڴص�SQL�ڵ��ϴ�������Ϊ��world�������ݿ⣬����ʹ��mysql�����пͻ��˶�ȡcity_table.sql������ͨ����ʽ����������Ӧ�ı���
shell> mysql world < city_table.sql
���ס�������������������SQL�ڵ��������ִ�У����ʮ����Ҫ�����ڱ�����Ӧ��IP��ַΪ192.168.0.20�Ļ�����ִ�С�
Ҫ����SQL�ڵ��ϴ����������ݿ�ĸ������뽫�ļ����浽/usr/local/mysql/data��Ȼ�����У�
shell> cd /usr/local/mysql/data
shell> mysql world < world.sql
��Ȼ��SQL�ű������ܱ�mysqlϵͳ�û���ȡ��������ļ����浽�˲�ͬ��Ŀ¼�£�������Ӧ�ĵ�����
ע�⣬��MySQL 5.1�У�NDB�ز�֧���Զ��������ݿ�Ĺ��ܣ�������Ҫ����μ�17.8�ڣ���MySQL�ص���֪���ơ���������ζ�ţ�һ����һ�����ݽڵ��ϴ��������磨world�����ݿ�����ı����ڴ��е�ÿ��SQL�ڵ��ϻ���Ҫ��������CREATE DATABASE world����MySQL 5.0.2��ʼ������ʹ��CREATE SCHEMA worldȡ����֮�������FLUSH TABLES���������ڵ����ʶ�����ݿⲢ��ȡ������塣
��SQL�ڵ�������SELECT��ѯ����MySQL���������κ�����ʵ�������в�ѯû������Ҫ������������в�ѯ������Ӧ����ͨ����ʽ��¼��MySQL��������
shell> mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.1.2-alpha
���롯help;����\h����ȡ���������롯\c����ջ�������
mysql>
����ڵ���MySQL�ű�֮ǰδ���ı������е�ENGINE=�Ӿ䣬Ӧ�ڴ�ʱ�����������
mysql> USE world;
mysql> ALTER TABLE City ENGINE=NDBCLUSTER;
mysql> ALTER TABLE Country ENGINE=NDBCLUSTER;
mysql> ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
ע�⣬���������Ǽ�ʹ����MySQL����������Ϊ�յ�Ĭ�ϸ��û��˻�����Ȼ�������������£���װMySQL������ʱ����Ӧ���ر��İ�ȫ������ʩ�����������ο��ĸ��û����룬��Ϊ�û���������������������Ȩ���û��˻��������ⷽ��ĸ�����Ϣ����μ�5.7�ڣ���MySQL����Ȩ��ϵͳ����
��Ҫ��ע���ǣ����ؽڵ�˴˷���ʱ��ʹ��MySQL��Ȩ��ϵͳ�����û����MySQL�û��˻����������û��˻�����Ӱ��ڵ�֮��Ľ��������ǽ��Է���SQL�ڵ��Ӧ�ó�����Ч��
�ܹ���ͨ���ķ�ʽѡ�����ݿ⣬���Ա�ִ��SELECT��ѯ�������˳�MySQL������һ����
mysql> USE world;
mysql> SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;
+-----------+------------+
| ���� | �˿� |
+-----------+------------+
| ���� | 10500000 |
| ���� | 9981619 |
| ʥ���� | 9968485 |
| �Ϻ� | 9696300 |
| �żӴ� | 9604900 |
+-----------+------------+
5 rows in set (0.34 sec)
mysql> \q
Bye
shell>
ʹ��MySQL��Ӧ�ó����ܹ�ʹ�ñ���API����Ҫ����Ӧ��ס�����Ӧ�ó���������SQL�ڵ㣬������MGM��洢�ڵ㡣������ļ�ʾ���У�������ʹ��PHP 5��mysqli��չ��������λ������������λ�õ�Web�������ϣ�ִ����ͬ��ѯ�ķ�����
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=iso-8859-1">
<title>SIMPLE mysqli SELECT</title>
</head>
<body>
<?php
# connect to SQL node:
$link = new mysqli('192.168.0.20', 'root', '', 'world');
# parameters for mysqli constructor are:
# host, user, password, database
if( mysqli_connect_errno() )
die("Connect failed: " . mysqli_connect_error());
$query = "SELECT Name, Population
FROM City
ORDER BY Population DESC
LIMIT 5";
# if no errors...
if( $result = $link->query($query) )
{
?>
<table border="1" width="40%" cellpadding="4" cellspacing ="1">
<tbody>
<tr>
<th width="10%">City</th>
<th>Population</th>
</tr>
<?
# then display the results...
while($row = $result->fetch_object())
printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n",
$row->Name, $row->Population);
?>
</tbody
</table>
<?
# ...and verify the number of rows that were retrieved
printf("<p>Affected rows: %d</p>\n", $link->affected_rows);
}
else
# otherwise, tell us what went wrong
echo mysqli_error();
# free the result set and the mysqli connection object
$result->close();
$link->close();
?>
</body>
</html>
���Ǽٶ�������Web�������ϵĽ����ܹ�����SQL�ڵ��IP��ַ��
�������Ƶķ����ʹ��MySQL C API��Perl-DBI��Python-mysql����MySQL AB�Լ�����������ִ�����ݶ���Ͳٿ�����������ʹ��MySQL������
�� ������ס��ÿ��NDB��������һ������������ڴ�����ʱ�û�δ����������NDB�ش洢���潫�Զ�������������������ע�ͣ������� ��Ҳ��ռ�ÿռ䣬�����κ������ı�����һ��������û���㹻���ڴ���������Щ�Զ������ļ����������Ⲣ����������
Ҫ��رմأ�����MGM�ڵ����ڵĻ����ϣ���Shell�м������������
shell> ndb_mgm -e shutdown
�����ǡ������ֹndb_mgm��ndb_mgmd�Լ��κ�ndbd���̡�ʹ��mysqladmin shutdown����������������ֹSQL�ڵ㡣ע�⣬����ġ�-e��ѡ�����ڽ������shell���ݵ�ndb_mgm�ͻ��ˡ���μ�4.3.1�ڣ�������������ʹ��ѡ���
Ҫ�������أ��ɼ������������
�� �ڹ��������ϣ���������Ϊ192.168.0.10����
�� shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
�� ��ÿ̨���ݽڵ������ϣ�192.168.0.30��192.168.0.40����
�� shell> ndbd
���ס����������NDBD�ڵ�ʱ����Ҫ�á�--initial��ѡ����ø����
�� ��SQL�����ϣ�192.168.0.20����
�� shell> mysqld &
���ڴ����ر��ݵĸ�����Ϣ����μ�17.6.5.2�ڣ���ʹ�ù����������������ݡ���
Ҫ��ӱ����лָ��أ���Ҫʹ��ndb_restore�����μ�17.6.5.3�ڣ�����λָ��ر��ݡ���
��������MySQL�صĸ�����Ϣ����μ�17.4�ڣ���MySQL�ص����á���
Ϊ�˱��ⲻ��Ҫ����Դ���䣬Ĭ������£��ڷ������������н���ֹNDB�洢���档Ҫ������NDB����Ҫ������������my.cnf�����ļ�����ʹ������ndbcluster��ѡ��������������
����MySQL�������Ǵص�һ���֣���Ҳ��Ҫ֪����η���MGM�ڵ㣬�Ա��ô��������ݡ�Ĭ����Ϊ�Dz��ұ���������MGM�ڵ㡣���ǣ������Ҫ����ָ������λ�ã�����my.cnf�ļ���MySQL�������������Ͻ��С��ܹ�ʹ��NDB�洢����֮ǰ������Ӧ��һ��MGM�ڵ��ǿɲ����ģ����һ�Ӧ����������ݽڵ㡣
17.4.1. ��Դ�봴��MySQL��
����Linux��Mac OS X��Solaris����������Ʒַ����о��ṩ��NDB�ش洢���档��Windowsƽ̨���в�֧�����������Ǵ����ڲ�Զ�Ľ���ʹ��������win32������ƽ̨��
���ѡ���Դ��tarball��MySQL 5.1 BitKeeper��������������configureʱ�����ʹ�á�--with-ndbcluster��ѡ�Ҳ����ʹ��BUILD/compile-pentium-max�����ű���ע�⣬�ýű�����OpenSSL����ˣ�Ҫ��ɹ������������л���OpenSSL���粻Ȼ����Ҫ���ġ�compile-pentium-max���Ա㽫��Ҫ���ų����⣬��Ȼ��Ҳ�ܲ��ñ��������������Լ��Ķ������ļ���Ȼ��ִ�г�����ԺͰ�װ���衣��μ�2.8.3�ڣ����ӿ���Դ������װ����
������������ڣ��ٶ�������Ϥ��MySQL�İ�װ�������ڴˣ����ǽ�������MySQL�������벻�߱��ع��ܵ�MySQL����֮��IJ�����ϣ���˽���ں��ߵĸ�����Ϣ����μ���2�£���װMySQL��
����������������еĹ��������ݽڵ㣬�㽫���ִ����������������ʱ������ò��֡��༭my.cnf�ļ����ֱ�ӣ��ڱ����У������������߱��ع��ܵ�MySQL���ò�ͬ�IJ��֡�
���ȣ�Ӧ��ϵͳ���û�����ͨ��ִ���������������Ŀ¼����/var/lib/mysql-cluster��
shell> mkdir /var/lib/mysql-cluster
�ڸ�Ŀ¼�£�ʹ��������Ϣ������Ϊconfig.ini���ļ������ϵͳ���������ǡ����ֵ�滻HostName��DataDir��
# file "config.ini" - showing minimal setup consisting of 1 data node,
# 1 management server, and 3 MySQL servers.
# The empty default sections are not required, and are shown only for
# the sake of completeness.
# Data nodes must provide a hostname but MySQL Servers are not required
# to do so.
# If you don't know the hostname for your machine, use localhost.
# The DataDir parameter also has a default value, but it is recommended to
# set it explicitly.
# Note: DB, API, and MGM are aliases for NDBD, MYSQLD, and NDB_MGMD
# respectively. DB and API are deprecated and should not be used in new
# installations.
[NDBD DEFAULT]
NoOfReplicas= 1
[MYSQLD DEFAULT]
[NDB_MGMD DEFAULT]
[TCP DEFAULT]
[NDB_MGMD]
HostName= myhost.example.com
[NDBD]
HostName= myhost.example.com
DataDir= /var/lib/mysql-cluster
[MYSQLD]
[MYSQLD]
[MYSQLD]
���ڣ��ܹ���������ʽ����������������
shell> cd /var/lib/mysql-cluster
shell> ndb_mgmd
��������ͨ������ndbd��������DB�ڵ㡣�״�Ϊ������DB�ڵ�����ndbdʱ��Ӧʹ�á���initial��ѡ�������ʾ��
shell> ndbd --initial
���ں�����ndbd������ͨ������Ҫʹ�ø�ѡ�
shell> ndbd
������Ϊ��--initialѡ�ɾ�������ݽڵ�������������ݺ���־�ļ����Լ����еı�Ԫ���ݣ����������µ����ݺ���־�ļ����ù����һ�������ǣ������������ݽڵ�������ز��ӱ��ݽ��лָ�֮ʱ��
Ĭ������£�ndbd���ڶ˿�1186�ϲ��ұ��������ϵĹ�����������
ע�ͣ�����Ӷ�����tarball��װ��MySQL����Ҫ��ȷָ��ndb_mgmd��ndbd��������·��������������£�����λ��/usr/local/mysql/binĿ¼�£���
�����MySQL����Ŀ¼��ͨ����/var/lib/mysql��/usr/local/mysql/data������ȷ��my.cnf�ļ���������NDB�洢���������ѡ�
[mysqld]
ndbcluster
���ڣ����ܰ�ͨ����ʽ����MySQL��������
shell> mysqld_safe --user=mysql &
�ȴ�һ��ʱ�䣬ȷ��MySQL����������ǡ�����С��������֪ͨ��mysqlֹͣ�������������.err�ļ����ҳ�����
�����ĿǰΪֹһ����������ʹ�ô���������
shell> mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.1.2-alpha-Max
���롯help;����\h����ȡ���������롯\c����ջ�������
mysql> SHOW ENGINES\G
...
*************************** 12. row ***************************
Engine: NDBCLUSTER
Support: YES
Comment: Clustered, fault-tolerant, memory-based tables
*************************** 13. row ***************************
Engine: NDB
Support: YES
Comment: Alias for NDBCLUSTER
...
��ע�⣬�����������ʾ���кſ��������ϵͳ����ʾ�IJ�ͬ���������ȡ����ʹ�õ�MySQL�汾���Լ��������ķ�ʽ����
shell> mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.1.2-alpha-Max
���롯help;����\h����ȡ���������롯\c����ջ�������
mysql> USE test;
Database changed
mysql> CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;
Query OK, 0 rows affected (0.09 sec)
mysql> SHOW CREATE TABLE ctest \G
*************************** 1. row ***************************
Table: ctest
Create Table: CREATE TABLE `ctest` (
`i` int(11) default NULL
) ENGINE=ndbcluster DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
Ҫ�����Ƿ�ǡ�������˽ڵ㣬�����������ͻ��ˣ�
shell> ndb_mgm
���Ϊ�˻�ù��ڴ�״̬�ı��棬�ɴӹ����ͻ�����ʹ��SHOW���
NDB> SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 1 node(s)
id=2 @127.0.0.1 (Version: 3.5.3, Nodegroup: 0, Master)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @127.0.0.1 (Version: 3.5.3)
[mysqld(API)] 3 node(s)
id=3 @127.0.0.1 (Version: 3.5.3)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
��ʱ����ɹ��������˹�����MySQL�ء����ڣ�����ʹ����ENGINE=NDBCLUSTER�������ENGINE=NDB�����ı��������ݱ��浽���С�
17.4.4. �����ļ�
����MySQL����Ҫ�������ļ�����
�� my.cnf��Ϊ���е�MySQL�ؿ�ִ���ļ�ָ����ѡ���Ӧ��Ϥ��ǰ����ܵ�ʹ��MySQL�ķ�ʽ��ͨ�������ڴ��е�ÿ����ִ���ļ��������ܹ����ʸ��ļ���
�� config.ini�����ļ�����MySQL�ع�����������ȡ���������������Ὣ�������ļ�����Ϣ��������е����н��̡�config.ini�ļ������Դ��и��ڵ���������������ݽڵ�����ò������Լ��������нڵ�����ӵ����ò�����
�������ڲ��ϸĽ������ã���Ŭ���ý��̡��������ǽ�����ά���������ԣ�����ijЩʱ����Ҳ��Ҫ���벻���ݵı䶯������������£����ǽ������ô��û������˽�ñ䶯�Ƿ��������ݵġ�����㷢������δ��¼���ĵ��е�����䶯����ʹ�����ǵ�ȱ�����ݿ�ͨ������
Ϊ��֧��MySQL�أ���Ҫ�����ļ�my.cnf����������ʾ��ע�⣬��Ӧ�����������ѡ����config.ini�ļ��г��ֵ�ѡ��������������⣬�������е��ÿ�ִ���ļ�ʱ������ҲӦָ����Щ������
# my.cnf
# example additions to my.cnf for MySQL Cluster
# (valid in MySQL 5.1)
# enable ndbcluster storage engine, and provide connectstring for
# management server host (default port is 1186)
[mysqld]
ndbcluster
ndb-connectstring=ndb_mgmd.mysql.com
# provide connectstring for management server host (default port: 1186)
[ndbd]
connect-string=ndb_mgmd.mysql.com
# provide connectstring for management server host (default port: 1186)
[ndb_mgm]
connect-string=ndb_mgmd.mysql.com
# provide location of cluster configuration file
[ndb_mgmd]
config-file=/etc/config.ini
�����������ַ��ĸ�����Ϣ����μ�17.4.4.2�ڣ���MySQL�������ַ���������
# my.cnf
# example additions to my.cnf for MySQL Cluster
# (will work on all versions)
# enable ndbcluster storage engine, and provide connectstring for management
# server host to the default port 1186
[mysqld]
ndbcluster
ndb-connectstring=ndb_mgmd.mysql.com:1186
��������Ҳ����ʹ�ô�my.cnf�е�����[mysql_cluster]���֣����ÿɱ����п�ִ���ļ���ȡ�����ã���Ӱ�����еĿ�ִ���ļ���
# cluster-specific settings
[mysql_cluster]
ndb-connectstring=ndb_mgmd.mysql.com:1186
Ŀǰ�������ļ����õ���INI��ʽ��Ĭ������±�����Ϊconfig.ini�����ļ�������ʱ��ndb_mgmd��ȡ�����ܱ������κεط���������������ndb_mgmdһ��ʹ��--config-file=[<path>]<filename>����ָ����λ�ú����ơ����δָ�������ļ���Ĭ������£�ndb_mgmd�����Զ�ȡλ�ڵ�ǰ����Ŀ¼�µ��ļ�config.ini��
���ڴ������������������Ĭ��ֵ��Ҳ����config.ini�ļ���ָ��Ĭ��ֵ��Ҫ�봴��Ĭ��ֵ���֣��ɼؽ�����DEFAULT���ӵ��ò��ֵ������ϡ����磬���ݽڵ���ʹ��[NDBD]�������õġ�������е����ݽڵ�ʹ����ͬ��С�������ڴ棬���Ҹ��ڴ��С��ͬ��Ĭ�ϵĴ�С��Ӧ��������DataMemory�е�[NDBD DEFAULT]���֣�Ϊ�������ݽڵ�ָ��Ĭ�ϵ������ڴ��С��
INI��ʽ����������֣�ÿһ�����Ըò��ֵı��⣨�÷�������ס����ʼ�����ǡ���IJ�������ֵ�������ʽ�IJ�֮ͬ�����ڣ�������ð�š�:���͵Ⱥš�=��������������ֵ����һ����ͬ�ǣ���Щ���ֲ�����������Ψһ��ʶ�ġ���Ψһ����Ŀ���������ͬ���͵�������ͬ�ڵ㣩����ΨһID��ʶ�ġ�
��Ϊ���Ҫ�������ļ����붨����еļ�����ͽڵ㣬�Լ���Щ�ڵ����ڵļ���������������һ���Ĵ������ļ�ʾ�����ôذ���1��������������2�����ݽڵ��2��MySQL��������
# file "config.ini" - 2 data nodes and 2 SQL nodes
# This file is placed in the startup directory of ndb_mgmd (the management
# server)
# The first MySQL Server can be started from any host. The second can be started
# only on the host mysqld_5.mysql.com
[NDBD DEFAULT]
NoOfReplicas= 2
DataDir= /var/lib/mysql-cluster
[NDB_MGMD]
Hostname= ndb_mgmd.mysql.com
DataDir= /var/lib/mysql-cluster
[NDBD]
HostName= ndbd_2.mysql.com
[NDBD]
HostName= ndbd_3.mysql.com
[MYSQLD]
[MYSQLD]
HostName= mysqld_5.mysql.com
�ڸ������ļ��У���6����ͬ���֣�
�� [COMPUTER]�������˴�������
�� [NDBD]�������˴ص����ݽڵ㡣
�� [MYSQLD]�������˴ص�MySQL�������ڵ㡣
�� [MGM]��[NDB_MGMD]�������˴صĹ����������ڵ㡣
�� [TCP]�������˴��нڵ���TCP/IP���ӣ�TCP/IP��Ĭ�ϵ�����Э�顣
�� [SHM]�������˽ڵ��Ĺ����ڴ����ӡ���ǰ���������ӽ�����ʹ�á�--with-ndb-shm��ѡ����Ķ������ļ���ʹ�á���MySQL 5.1-Max�У�Ĭ����������������ģ�����Ӧ������Ϊ�����Եġ�
ע�⣬ÿ���ڵ���config.ini�ļ������Լ��IJ��֡����磬���ڸô����������ݽڵ㣬�������ļ��У�Ҳ����������Щ�ڵ�IJ��֡�
����Ϊÿ�����ֶ���DEFAULTֵ�����еĴز������ƾ����ִ�Сд��
����MySQL�ع�����������ndb_mgmd��������MySQL�ص�ÿ���ڵ����Ҫ1�������ַ������������ַ���ָ��������������ڵ�λ�á������ڽ�������������������ӣ���ִ����������������������ȡ���ڽڵ��ڴ��ڰ��ݵĽ�ɫ�������ַ���������£�
<connectstring> :=
[<nodeid-specification>,]<host-specification>[,<host-specification>]
<nodeid-specification> := node_id
<host-specification> := host[:port]
node_id�Ǵ���1������������ȷ��config.ini�еĽڵ㡣port����������Unix�˿ڵ�������host�Ǵ�����ЧInternet��ַ���ַ�����
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200"
example 2 (short): "myhost1"
���δ�ṩ�����нڵ����ʹ��localhost:1186��ΪĬ�ϵ������ַ���ֵ������������ַ�����ʡ����<port>��Ĭ�϶˿�Ϊ1186���ö˿�����������Ӧ�ǿ��õģ�������Ϊ������IANAΪ��Ŀ�Ķ�ָ���ģ�������μ�http://www.iana.org/assignments/port-numbers����
ͨ���г����<host-specification>ֵ���ܹ�ָ����������������������ؽڵ㽫����ָ����˳�������ӵ�ÿ̨�����ϵ�����������������ֱ���ɹ�����������Ϊֹ��
�ж���ָ�������ַ����IJ�ͬ������
�� ÿ����ִ���ļ����Լ���������ѡ�ʹ�������ܹ�������ʱָ�����������������ڸ���ִ�г���Ľ��ܣ���μ���Ӧ���ĵ�����
�� Ҳ��һ���Ե�Ϊ���е����нڵ����������ַ����������ǽ�����ڹ�����������my.cnf�ļ���[mysql_cluster]���֡�
�� Ϊ���������ԣ����ṩ����������ѡ���ʹ�õ����ͬ��
1. ����NDB_CONNECTSTRING����������ʹ֮����connectstring�������ַ�������
2. ����Ը���ִ���ļ���connectstring�������ַ�����д����ΪNdb.cfg���ı��ļ����������ļ����ڿ�ִ���ļ�������Ŀ¼�¡�
���ǣ���Щ����Ŀǰ�Ѳ��������ӣ������°�װ����Ӧʹ�����ǡ�
ָ�������ַ���ʱ���Ƽ��ķ�������������������������Ϊÿ����ִ���ļ���my.cnf�ļ�����������
�������ڱ���Ϊϵͳ�е�ÿ���ڵ㶨���������⣬[COMPUTER]����û��ʵ�ʵ���Ҫ���塣�������ᵽ�����в���������Ҫ�ġ�
�� [COMPUTER]Id
��������ֵ����������λ�������ļ��б������������
�� [COMPUTER]HostName
���Ǽ��������������IP��ַ��
[NDB_MGMD]�������������[MGM]���������ù�������������Ϊ�������г������в������ܱ����ԣ��������������ʹ����Ĭ��ֵ��ע�ͣ����ExecuteOnComputer��HostName������δ���֣���Ϊ����ָ��Ĭ��ֵlocalhost��
�� [NDB_MGMD]Id
���е�ÿ���ڵ㶼��Ψһ�ı�ʶ���ɴ�1��63��������ʾ�����е��ڲ�����Ϣʹ�ø�ID����ַ��㡣
�� [NDB_MGMD]ExecuteOnComputer
��������[COMPUTER]�����ж���ļ����֮һ��
�� [NDB_MGMD]PortNumber
���ǹ������������ڼ������������������Ķ˿ںš�
�� [NDB_MGMD]LogDestination
�ò���ָ���˽��ص�¼��Ϣ���͵����������ѡ�CONSOLE��SYSLOG��FILE��
o CONSOLE������־�����������豸��stdout����
o CONSOLE
o SYSLOG������־���͵�syslog��ϵͳ��־�����豸�����ܵ�ֵ������auth��authpriv��cron��daemon��ftp��kern��lpr��mail��news��syslog��user��uucp��local0��local1��local2��local3��local4��local5��local6��local7��
ע�ͣ��������еIJ���ϵͳ��֧�����е����豸��
SYSLOG:facility=syslog
o FILE��������־���������ͬ�����ϵ������ļ�����ָ������ֵ��
�� filename����־�ļ������ơ�
�� maxsize����־��¼�л������ļ�֮ǰ���ļ��������������ߴ硣���ָ����ʱ����ͨ�����ļ���������.x����������־�ļ������У�x�Ǹ�������δʹ�õ���һ�����֡�
�� maxfiles����־�ļ��������Ŀ��
o FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
ʹ���ɷֺŷָ����ַ���������ָ�������־Ŀ�꣬������ʾ��
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
FILE������Ĭ��ֵ��FILE:filename=ndb_node_id_cluster.log,maxsize=1000000,maxfiles=6�����У�node_id�ǽڵ��ID��
�� [NDB_MGMD]ArbitrationRank
�ò������ڶ����ĸ��ڵ㽫�����ٲó���Ľ�ɫ��ֻ��MGM�ڵ��SQL�ڵ��ܰ����ٲó���Ľ�ɫ��ArbitrationRank����ȡ����ֵ֮һ��
o 0���ýڵ���Զ���������ٲó���
o 1���ýڵ���иߵ����ȼ���Ҳ����˵��������ȼ��ڵ���ȣ��������׳�Ϊ�ٲó���
o 2�������ڵ���е͵����ȼ����������и����ȼ��Ľڵ������ڸ�Ŀ��ʱ�����ܳ�Ϊ�ٲó���
ͨ������£�Ӧ��ArbitrationRank����Ϊ1��Ĭ��ֵ�����������е�SQL�ڵ�����Ϊ0������������������Ϊ�ٲó���
�� [NDB_MGMD]ArbitrationDelay
����ֵ���Ժ���Ϊ��λ�涨�˹������������ٲ�������ӳ�ʱ�䡣Ĭ������£���ֵΪ0��ͨ������Ҫ�ı�����
�� [NDB_MGMD]DataDir
���������ñ����������������ļ���λ�á���Щ�ļ���������־�ļ�����������ļ����Լ��˿ڼල�����pid�ļ���������־�ļ�����ͨ������[NDB_MGMD]LogDestination��FILE��������������μ�����ǰ������ۣ���
[NDBD]�����������ô����ݽڵ����Ϊ���кܶ�����ڿ��ƻ�������С���ش�С����ʱ�ȵIJ�����ǿ���Բ���������
�� ExecuteOnComputer��HostName.
�� ����NoOfReplicas
��Щ������Ҫ��[NDBD DEFAULT]�����ж��塣
��������ݽڵ��������[NDBD DEFAULT]���������õġ�ֻ����Щ��ȷ����Ϊ�����ñ���ֵ�IJ���������[NDBD]�����б����ġ�HostName��Id�Լ�ExecuteOnComputer�����ڱ���[NDBD]�����ж��塣
ʶ�����ݽڵ�
�����ڵ�ʱ�������������Ϸ���Idֵ�������ݽڵ�ID����Ҳ���������ļ��з���Idֵ��
���ڸ��������ܹ�ʹ�ú�k��M��G����ָ����λ���ֱ��ʾ1024��1024*1024��1024*1024*1024�����磬100k��ʾ100 * 1024 = 102400����Ŀǰ��������ֵ���ִ�Сд��
�� [NBDB]Id
���������ڵ��ַ�Ľڵ�ID�����еĴ��ڲ���Ϣʹ�á����ǽ���1��63֮������������е�ÿ���ڵ����Ψһ��ID��
�� [NDBD]ExecuteOnComputer
����������COMPUTER�����ж���ļ��������������
�� [NDBD]HostName
ָ���ò�����Ч��������ָ��ExecuteOnComputer���������˴洢�ڵ����ڼ��������������ָ����localhost֮�������������ʱ����Ҫ�ò�����ExecuteOnComputer��
�� (OBSOLETE) [NDBD]ServerPort
���еĸ��ڵ�ʹ�ö˿����������ڵ��������ö˿�Ҳ�������ӽ������еķ�TCP������������Ĭ�϶˿��Ƕ�̬����ģ�ͬһ̨������ϵ������ڵ���в�ͬ�Ķ˿ںţ���������²���ҪΪ�ò���ָ��ֵ��
�� [NDBD]NoOfReplicas
��ȫ�ֲ���������[NDBD DEFAULT]�����ã��������˴���ÿ��������ĸ��������ò�����ָ���˽ڵ���Ĵ�С���ڵ���ָ���DZ�����ͬ��Ϣ�Ľڵ㼯�ϡ�
�ڵ���������ʽ��ʽ���ɵġ���1���ڵ����ɾ�����ͽڵ�ID�����ݽڵ㼯�Ϲ��ɣ���һ���ڵ����ɾ��дεͽڵ�ID�����ݽڵ㼯�Ϲ��ɣ��������ơ���Ϊʾ�����ض�������4�����ݽڵ㣬����NoOfReplicas����Ϊ2�����ĸ����ݽڵ��ID�ֱ���2��3��4��5����ô��1���ڵ����ɽڵ�2��3���ɣ���2���ڵ����ɽڵ�4��5���ɡ���Ҫ���ǶԴؽ�����Ӧ�����ã�ʹ��ͬһ�ڵ����еĽڵ�λ�ڲ�ͬ�ļ�����ϣ�������Ϊ�����λ����ͬ�ļ�����ϣ�����Ӳ�����ϻᵼ�������ر�����
���δ�ṩ�ڵ�ID����ô���ݽڵ��˳���ǽڵ���ľ������ء������Ƿ��������ȷ�ķ��䣬���ڹ����ͻ���SHOW���������в鿴���ǡ�
NoOfReplicasû��Ĭ��ֵ�����Ŀ���ֵΪ4��
�� [NDBD]DataDir
�ò���ָ���˴�Ÿ����ļ�����־�ļ���pid�ļ��Լ�������־��Ŀ¼��
�� [NDBD]FileSystemPath
�ò���ָ���˴��ΪԪ���ݴ����������ļ���REDO��־��UNDO��־�������ļ���Ŀ¼��Ĭ��Ŀ¼����DataDirָ���ġ�ע�⣬����ndbd����֮ǰ����Ŀ¼�����Ѵ��ڡ�
ΪMySQl���Ƽ���Ŀ¼��ΰ���/var/lib/mysql-cluster��������Ϊ�ڵ���ļ�ϵͳ����1��ΪĿ¼������Ŀ¼�����ڵ�ID�����磬����ڵ�IDΪ2������Ŀ¼������Ϊndb_2_fs��
�� [NDBD]BackupDataDir
Ҳ��ָ����ű��ݵ�Ŀ¼��Ĭ������£���Ŀ¼��FileSystemPath/BACKUP����μ�ǰ��Ľ��ܣ���
�����ڴ�������ڴ�
����DataMemory��IndexMemoryָ���˴��ʵ�ʼ�¼�����������ڴ�εĴ�С���������ǵ�ֵʱ����Ҫ����Ӧ����ʹ��DataMemory��IndexMemory�ķ�ʽ��������Ϊ��Ϊ�˷�ӳ�ص�ʵ��ʹ�������������Ҫ�������ǣ�
�� [NDBD]DataMemory
�ò������������ڱ������ݿ��¼�Ŀռ��С��ȫ���ռ���Ƿ������ڴ��еģ���ˣ�����Ӧ�����㹻�������ڴ������ɸ�ֵ����㼫����Ҫ��
��DataMemory������ڴ����ڱ���ʵ�ʼ�¼��������Ŀǰ��ÿ����¼���й̶��Ĵ�С������VARCHAR��Ҳ����Ϊ�̶������У���ÿ����¼�Ŀ���Ϊ16�ֽڣ����⣬ÿ����¼����Ҫ����Ŀռ䣬������Ϊ�������¼�����ھ���128�ֽ�ҳ�濪����32KBҳ�У���μ�����Ľ��ܣ�������ÿ����¼��������1��ҳ�У����ÿҳ���������˷ѡ�Ŀǰ������¼��СΪ8052�ֽڡ�
��DataMemory������ڴ�ռ�Ҳ���ڱ�����������������ÿ����¼������Լʹ��10�ֽڡ������������У���ʾ��ÿ�����С��û�������һ�������ǣ��뵱Ȼ����Ϊ���е���������������IndexMemory������ڴ��У������������ˣ�ֻ��������Ψһ�Ի������ʹ�ø��ڴ棬��������ʹ�õ�����DataMemory������ڴ档Ȼ��������������Ψһ�Ի������ʱ��Ҳ������ͬ�� ���ϴ��������������������������������ָ����USING HASH��ͨ���ڹ����ͻ���������ndb_desc -d db_name table_name���ɶ��������֤��
DataMemory������ڴ�ռ��ɶ��32KBҳ���ɣ�������Ϊ��Ƭ�η���ġ�ͨ������£�Ϊÿһ�����ֵı�Ƭ����Ŀ����еĽڵ���Ŀ��ͬ����ˣ�����ÿһ�ڵ㣬Ƭ����Ŀ����NoOfReplicas�����õ���ͬ��һ��������1ҳ��Ŀǰ�����䷵�ص�����ҳ���У�����ɾ������ִ�нڵ�ָ�Ҳ��ѹ��������������Ϊ�����м�¼���ᱻ���뵽������ڵ�Ŀշ����С�
DataMemory�ڴ�ռ�Ҳ����UNDO��Ϣ������ÿһ���£�δ�ı��¼�ĸ����������䵽DataMemory�С�������������У����ж�ÿһ���������á���������Ψһ��������ʱ���Ż����Ψһ�Ի���������ڸ�����£������������в����µ���Ŀ�������ύʱɾ���ɵ���Ŀ����ˣ�Ҳ�б�Ҫ�����㹻���ڴ棬�Ա㴦����ʹ�ôص�Ӧ�ó���ִ�е�����������κ�����£�ִ���������������ʹ���ڶ�С������ռ�ţ�ԭ�����£�
o ��������ٶ�û�н�С������ٶȿ졣
o �����������Ӷ�ʧ��������Ŀ��һ������ʧ�ܣ������ظ�ִ�С�
o �������ʹ�ø�����ڴ档
DataMemory��Ĭ��ֵ��80MB����СΪ1MB��û�����ߴ����ƣ�����ʵ��ʹ�ù����У��������Ӧǡ�����Ա㵱�ﵽ�������ʱ�����̲��������������ܡ��������ɻ����Ͽ��õ�����RAM�����Լ�����ϵͳ���ύ���κν��̵��ڴ�������������32λ����ϵͳ��������ֵΪÿ����2��4GB������64λ����ϵͳ��������ֵ�����ڴ�����ݿ⣬���ڸ�ԭ�����ʹ��64λ����ϵͳ�����⣬��ÿ̨������Ҳ������һ�����ϵ�ndbd���̣���ʹ�ö�CPU�Ļ����ϣ��������ľ����ơ�
�� [NDBD]IndexMemory
�ò������ڿ���MySQL���й�ϣ����ࣩ������ʹ�õĴ洢������ϣ����ࣩ��������������������Ψһ���������Լ�Ψһ��Լ����ע�⣬����������Ψһ������ʱ����������������������һ������������tuple���ʺ����������Ĺ�ϣ����ࣩ���������⣬������������ǿΨһ��Լ����
��ϣ����ࣩ�����Ĵ�С��ÿ��¼25�ֽڣ��ټ��������Ĵ�С���Դ���32�ֽڵ��������������8�ֽڡ�
������������ı���
CREATE TABLE example (
a INT NOT NULL,
b INT NOT NULL,
c INT NOT NULL,
PRIMARY KEY(a),
UNIQUE(b)
) ENGINE=NDBCLUSTER;
��12�ֽڵĿ������ɿ��н���ʡ4�ֽڵĿ���������ÿ��¼12�ֽڵ����ݡ����⣬����a��b�������������������ٶ�ÿ��¼�ֱ����Լ10�ֽڵĿռ䡣��ÿ��¼Լʹ��29�ֽڵĻ�������1��������ϣ������Ψһ��Լ������b��Ϊ�����Լ�a��Ϊ�еĵ�����ʵ�֡����ڸñ���ÿ��¼�����ö����29�ֽ������ڴ棬��ʾ�����У�������12�ֽڵĿ����ټ���8�ֽڵļ�¼���ݡ�
��ˣ�����100������¼����Ҫ58MB�������ڴ�����������������Ψһ��Լ���Ĺ�ϣ����������Ҫ64 MB������������Ψһ���������Լ����������������ļ�¼��
�ɴ˿ɼ�����ϣ����ռ�����൱����ڴ�ռ䣬����Ϊ�ر��������ṩ�˶����ݵļ�����ʡ���MySQl���У�����Ҳ���ڴ���Ψһ��Լ����
Ŀǰ���еķ����㷨��ɢ�з�������������ÿ���ڵ���˵���Ǿֲ��Եġ���ˣ����������������ڴ���һ������µ�Ψһ��Լ����
����IndexMemory��DataMemory����Ҫ���ǣ��ܵ����ݿ��С�Ǹ��ڵ�������������ڴ�����������ڴ�֮�͡�ÿ���ڵ������ڱ��渴����Ϣ����ˣ������4���ڵ��2������������2���ڵ��顣����ÿ�����ݽڵ㣬���õ��������ڴ���2*DataMemory��
ǿ�ҽ���Ϊ���еĽڵ�������ͬ��DataMemoryֵ��IndexMemoryֵ������������ƽ���ֲ��ڴ��е����нڵ��ϣ��κνڵ���õ����ռ䲻����������С�ڵ�Ŀ��ÿռ䡣
DataMemory��IndexMemory�ɱ����ģ��������κ�һ����ֵ���ᵼ��Σ�գ������������������ʹijһ�ڵ�������������ȱ���㹻���ڴ�ռ�����������������ǵ�ֵӦ�ǿɽ��ܵģ����������������������ͬ�ķ�ʽ�����������ȸ��������ļ���Ȼ�����������������������������ÿ�����ݽڵ㡣
���²����������õ������ڴ档���뽫������Ч�����ǣ����ύ����֮ǰ������ʵ��ɾ���С�
IndexMemory��Ĭ��ֵ��18MB����СֵΪ1MB��
�������
�������۵���������ʮ����Ҫ��������Ϊ�����ǻ�Ӱ�첢���������Ŀ���Լ�ϵͳ�ܹ�����������Ĵ�С��MaxNoOfConcurrentTransactions�������ýڵ��ڿ��ܵIJ���������Ŀ��MaxNoOfConcurrentOperations����������ͬʱ�����ڸ��½λ�ͬʱ�����ļ�¼��Ŀ��
���ڴ����趨�ض�ֵ����ʹ��Ĭ��ֵ���û�����������������������������ģ�������MaxNoOfConcurrentOperations����Ĭ��ֵ��Ϊʹ��С�������ϵͳ�����õģ�Ϊ����ȷ����������ʹ�ù�����ڴ档
�� [NDBD]MaxNoOfConcurrentTransactions
���ڴ��е�ÿ����������ڴؽڵ�֮һ����1����¼���������Э���������ڸ��ڵ����еģ��ڴ��У������¼������������������ڵ��е����������Դ��еĽڵ�����
�����¼�������������MySQL����������������£�����ʹ�ô����κα���ÿ�����ӣ�����Ϊ���������1�������¼�����ڸ�ԭ��Ӧȷ�����е������¼�����ڴ�������MySQL�������IJ�����������
�������еĴؽڵ㣬���뽫�ò�������Ϊ��ͬ��ֵ��
���ĸò�������ȫ��������������ᵼ�´ر�������ijһ�ڵ����ʱ�����е�һ���ڵ㣨ʵ����������ʱ����õĽڵ㣩��Ϊ����֮ʱ���ڱ����ڵ������е���������������״̬����ˣ���Ҫ���ǣ��ýڵ�������¼��������ʧЧ�ڵ��е������¼����
�ò�����Ĭ��ֵΪ4096.
�� [NDBD]MaxNoOfConcurrentOperations
��������Ĵ�С����Ŀ�����ò�����ֵ������뷨������ִ�н��������������Ҳ��漰�ܶ��¼������ʱ������Ҫ���ò������õúܸߡ�����ִ���漰������¼�Ĵ�����ʱ����Ҫ���ò������õýϸߡ�
����ÿ��������µĴ����ݣ����ᱣ���¼�����Ὣ���DZ���������Э�������Լ�ִ��ʵ�ʸ��µĽڵ��С���Щ��¼���������״̬��Ϣ��������Ϣ������Ϊ�ع������ҵ�UNDO��¼������������ѯ������Ŀ�ġ�
�ò���Ӧ������Ϊ��������ͬʱ���µļ�¼�����Դ����ݽڵ����Ŀ�����磬�ڰ���4�����ݽڵ�Ĵ��У����Ԥ�ڴ����ġ�ʹ������IJ���������Ϊ1000000����Ӧ����ֵ����Ϊ1000000 / 4 = 250000��
���������Ķ�����Ҳ�ᵼ�²�����¼�Ĵ������ڵ����ڵ���Ҳ�����һЩ����Ŀռ䣬�Ա㴦���ڽڵ����䲻���������⡣
����ѯʹ��Ψһ�Թ�ϣ����ʱ�����������е�ÿ����¼��ʵ���Ͻ�ʹ������������¼����1����¼�������������еĶ�����2����¼�����������ϵIJ�����
�ò�����Ĭ��ֵΪ32768.
�ò���ʵ���ϴ��������ֱܷ����õ�����ֵ����1��ֵָ���˽����ٲ�����¼�ŵ�����Э�����У���2��ֵָ���˶��ٲ�����¼�����ݿ�ı��ؼ�¼��
������8�ڵ����ִ�е��ش�������Ҫ������Э�����еIJ�����¼���������������漰�Ķ�ȡ�����º�ɾ��������Ȼ�������еIJ�����¼�ֲ������е�8���ڵ��ϡ���ˣ�����б�ҪΪ�ش���������ϵͳ�����õķ����Ƿֱ����øò������������֡�MaxNoOfConcurrentOperations�ܻᱻ���ڼ����ڵ������Э���������еIJ�����¼����
Ӧ�˽������¼���ڴ��Ҫ�����Ҳ����Ҫ��ÿ��¼Լ����1KB��
�� [NDBD]MaxNoOfLocalOperations
Ĭ������£�������1.1 * MaxNoOfConcurrentOperations����ò��������ʺ��ھ��кܶಢ�����������ش������ϵͳ�������Ҫ��ijһʱ�䴦���ش���������кܶ�ڵ㣬���ͨ����ȷָ���ò����Ը���Ĭ��ֵ��
������ʱ�洢
��һ��������ھ���ִ����Ϊ��������ɲ��ֵIJ�ѯʱ�������ʱ�洢�ռ䡣��ѯ��ɺ��ͷ����м�¼���ؽ��ȴ��ύ��ع��¼���
���ڴ�����������Щ������Ĭ��ֵ��ǡ���ġ����ǣ������Ҫ֧���漰�����л�����������û�����Ӧ������Щ������ֵ���Ա���ϵͳ�л�ø��õ�ƽ���ԡ�������Ҫ��Խ��������Ӧ�ó����û��ɽ�����Щ������ֵ���Ա��ʡ�ڴ档
�� [NDBD]MaxNoOfConcurrentIndexOperations
����ʹ��Ψһ�Թ�ϣ�����IJ�ѯ���ڲ�ѯִ���ڼ䣬��ʹ�ò�����¼����һ����ʱ���ϡ��ò����������ü�¼�صĴ�С����ˣ�����ִ�в�ѯ��ijһ����ʱ�Ż����ü�¼��һ���ò���ִ����ɣ����ͷż�¼�����ڴ����������ύ�����״̬�������������IJ�����¼�������ģ������¼�ijش�С�ɲ���MaxNoOfConcurrentOperations���á�
�ò�����Ĭ��ֵΪ8192��ֻ���ڼ��亱��������£���Ҫʹ��Ψһ�Թ�ϣ����ִ�м��ߵIJ��в���ʱ�����б�Ҫ�����ֵ�����DBA�����ݿ����Ա��ȷ�Ÿôز���Ҫ�ߵIJ��в���������ʹ�ý�С��ֵ����ʡ�ڴ档
�� [NDBD]MaxNoOfFiredTriggers
MaxNoOfFiredTriggers��Ĭ��ֵ��4000��������Ӧ��������������ijЩ����£����DBA��Ϊ�ڴ��жԲ��в�����Ҫ���ߣ��������ܽ�������
ִ�л�Ӱ��Ψһ��ϣ�����IJ���ʱ����������¼���ھ��й�ϣ�����ı��в����ɾ����¼ʱ���������ΪΨһ��ϣ������ɲ��ֵ���ʱ�����ᴥ���������еIJ����ɾ������������õļ�¼���ڴ�����������������ͬʱ�ȴ���ʹ����ɵij�ʼ�������ò�����ʱ��̣ܶ��������ڻ���������Ψһ��ϣ���������кܶಢ��д���������Σ�����Ҫ�ڼ�¼�����д����ļ�¼��
�� [NDBD]TransactionBufferMemory
�ò���Ӱ����ڴ����ڸ��ٸ����������Ͷ�ȡΨһ����ʱִ�еIJ��������ڴ����ڱ��������������ļ�������Ϣ����������Ҫ���ĸò�����Ĭ��ֵ��
�����Ķ���д����ʹ�����ƵĻ���������ʹ��ʱ���������̡�����ʱ�����ZATTRBUF_FILESIZE����ndb/src/kernel/blocks/Dbtc/Dbtc.hpp�У�����Ϊ4000*128�ֽڣ�500KB�������� ����Ϣ�����ƻ�������ZDATABUF_FILESIZE��Ҳ��Dbtc.hpp�У�����4000 * 16 = 62.5KB�Ļ���ռ䡣Dbtc�����ڴ�������Э����ģ�顣
ɨ��ͻ���
��Dblqhģ��������ndb/src/kernel/blocks/Dblqh/Dblqh.hpp�ڣ��кܶ�Ӳ�������Щ������Ӱ�����д��������Щ����������ZATTRINBUF_FILESIZE��Ĭ��ֵΪ10000*128�ֽڣ�1250KB�����Լ�ZDATABUF_FILE_SIZE��Ĭ�ϵĻ���ռ��СΪ10000*16�ֽڣ�Լ156KB������ĿǰΪֹ��û���κμ������Ӧ�����������ʱ�����Ʋ�����ֵ���������û����滹�������Լ��Ĵ������ԡ�
TransactionBufferMemory��Ĭ��ֵ��1MB��
�� [NDBD]MaxNoOfConcurrentScans
�ò������ڿ��ƿ��ڴ���ִ�еIJ���ɨ�����Ŀ��ÿ������Э��������ܴ���Ϊ�ò�������IJ���ɨ�衣����ÿ��ִ�е�ɨ���ѯ�����Բ��з�ʽɨ�����з�����ÿ�η���ɨ�轫ʹ�÷������ڽڵ��ڵ�ɨ���¼����¼�����ڸò�����ֵ���Խڵ�������Ӧ��֧�ִӴ������нڵ�ͬʱִ�е�MaxNoOfConcurrentScansɨ�衣
ɨ��ʵ�����������������ִ�еġ���1������ǣ�������ѯʱ�����ڹ�ϣ�������������ڸ�����£���ѯ��ͨ��ִ��ȫ��ɨ����еġ���2������ǣ�û��֧�ֲ�ѯ�Ĺ�ϣ����������������������ʹ������������ζ�Ž�ִ�в�����Χɨ�衣����˳��������ڱ��ط����ϣ���Ҫ�����з�����ִ������ɨ�衣
MaxNoOfConcurrentScans��Ĭ��ֵ��256�����ֵΪ500��
�ò���ָ��������Э�����еĿ���ɨ���������δ�ṩ����ɨ���¼����Ŀ���������м��㣬����MaxNoOfConcurrentScans����ϵͳ�����ݽڵ����Ŀ��
�� [NDBD]MaxNoOfLocalScans
����ܶ�ɨ�費����ȫ���л��ģ�ָ������ɨ���¼����Ŀ��
�� [NDBD]BatchSizePerLocalScan
�ò������ڼ���������¼����Ŀ��Ҫ�봦���ܶಢ��ɨ���������Ҫ�����¼��
Ĭ��ֵ��64����ֵ��SQL�ڵ��ж����ScanBatchSize��ϵ���С�
�� [NDBD]LongMessageBuffer
���������ڵ����ڵ��ںͽڵ�֮�䴫����Ϣ���ڲ����塣���ܼ�������Ҫ�ı������������ǿ����õġ�Ĭ������£���������Ϊ1MB��
��־��Checkpointing
�� [NDBD]NoOfFragmentLogFiles
�ò����������ýڵ��REDO��־�ļ��Ĵ�С��REDO��־�ļ��ǰ�ѭ����ʽ��֯�ġ���1�������1����־�ļ�����ʱҲ�ֱ��Ϊ��ͷ����־�ļ��͡�β����־�ļ�����Ӧ��������㼫����Ҫ�������DZ˴˹��ڽӽ�ʱ������ȱ������־��¼�Ŀռ䣬�ڵ㽫��ʼ�����������������¡�
�Բ�����־��¼��ʼ�����������ؼ������֮ǰ������ɾ��REDO��־��¼�������Ƶ�������Լ������ò�������������μ����µ���Ӧ���֡�
Ĭ�ϵIJ���ֵΪ8������ʾ��8�����ϣ�ÿ��������4��16MB�ļ���������Ϊ512MB�����仰����REDO��־�ռ���밴64MB�Ŀ��С���䡣����Ҫ�������µ�����£�������Ҫ��NoOfFragmentLogFiles��ֵ���ӵ�300����ߣ��Ա�ΪREDO��־�ṩ�㹻�Ŀռ䡣
���checkpointing���������кܶ�����ݿ��д������������־�ļ�������������û��jeapo rdising�ָ����ܵ���������ض���־β������ô���еĸ�����־�������������������������410��ȱ����ʱ��־�ռ䡣��״����һֱ������ֱ������˼���������ܽ���־β����ǰ�ƶ�Ϊֹ��
�� [NDBD]MaxNoOfSavedMessages
�ò����������ø����ļ��������Ŀ���ڸ��Ǿ��ļ�֮ǰ����������Щ�����ļ������۳��ں���ԭ���ڵ����ʱ�����������ļ���
Ĭ��Ϊ25�������ļ���
Ԫ���ݶ���
��һ�����ΪԪ���ݶ������˳صĴ�С�������ڶ����������������������������ʹ�õĴ�����������¼����Լ���֮��ĸ��ơ�ע�⣬��Щ�������ǶԴصġ����顱���κ�δָ���IJ�������������Ĭ��ֵ��
�� [NDBD]MaxNoOfAttributes
�����˿��ڴ��ж����������Ŀ��
�ò�����Ĭ��ֵΪ1000����С�Ŀ���ֵΪ32��û�����ֵ���ơ�����ÿһ���ԣ�ÿ�ڵ�Լ��200�ֽڵĴ洢�ռ䣬����ӦΪ�����е�Ԫ���ݽ������ظ��Ƶ��������ϡ�
����MaxNoOfAttributesʱ��Ӧʵ�����ô����ڽ���ִ�е��κ�ALTER TABLE���������Ҫ��������Ϊ������ʵ���ڴر���ִ��ALTER TABLE�Ĺ����У���ʹ�õ�������Ŀ��ԭʼ���е�3�������磬���ijһ����Ҫ100�����ԣ�������������Ժ����������ô����Ҫ��MaxNoOfAttributes��ֵ��Ϊ300����һ�����õľ��������������ڲ��������������´�����������ı����뽫������������Ŀ�������ӵ�MaxNoOfAttributes�ϡ���ɸ����ú�Ӧͨ��ִ��ʵ�ʵ�ALTER TABLE��������֤����Ŀ���㹻�ġ����ʧ�ܣ���ԭʼֵ�ı����ӵ�MaxNoOfAttributes�ϣ����ٴβ��ԡ�
�� [NDBD]MaxNoOfTables
��������Ϊÿ������Ψһ��ϣ������������������ġ��ò���Ϊ��Ϊ����Ĵ�����������������Ŀ��
���ھ���BLOB�������͵�ÿ�����ԣ���ʹ�ö���ı��������BLOB���ݡ������������ʱ�����뽫��Щ���������ڡ�
�ò�����Ĭ��ֵΪ128����СֵΪ8�����ֵΪ1600��ÿ��������ÿ�ڵ�Լ��20KB�Ŀռ䡣
�� [NDBD]MaxNoOfOrderedIndexes
���ڴ��е�ÿ������������������1�����ö��������˱�����������ʲô�Լ���洢�Ρ�Ĭ������£�ÿ�����������������������1������������ÿ��Ψһ��������������1��������������1����ϣ������
�ò�����Ĭ��ֵΪ128��ÿ������ÿ�ڵ�Լ��10KB�����ݡ�
�� [NDBD]MaxNoOfUniqueHashIndexes
����ÿ������������Ψһ������������1����������ñ���Ψһ��ӳ�䵽�������������ϡ�Ĭ������£�����ÿ��Ψһ��������������1������������Ϊ�˷�ֹ�����������Ψһ����ʱ������ʹ��USING HASHѡ�
Ĭ��ֵ��64��ÿ������ÿ�ڵ�Լ��15KB�Ŀռ䡣
�� [NDBD]MaxNoOfTriggers
����ÿ��Ψһ�Թ�ϣ�������������ڲ����¡����롢��ɾ��������������ζ�Ŷ���ÿ��Ψһ�Թ�ϣ���������������������������ǣ�1��������������Ҫ1��������������ڴ���ÿ��������������Ҳ��ʹ�����������������
ע����֧�ִ�֮��ĸ���ʱ��Ҳ��ʹ���ڲ���������
�ò����������ô��д����������������Ŀ��
�ò�����Ĭ��ֵΪ768.
�� [NDBD]MaxNoOfIndexes
��MySQL 5.1�У��ò����ѱ�������Ӧʹ��MaxNoOfOrderedIndexes��MaxNoOfUniqueHashIndexesȡ����֮��
�ò�������Ψһ�Թ�ϣ����ʹ�á������ڴ��ж����ÿ��Ψһ�Թ�ϣ�������ڸó�����Ҫ��1����¼��
�ò�����Ĭ��ֵΪ128.
��������
���ݽڵ����ΪҲ���ܾ��в���ֵ��һ�������Ӱ�졣������Ϊ��1����Y�����ɽ������������Ϊ���桱��������Ϊ��0����N�����ɽ������������Ϊ���١���
�� [NDBD]LockPagesInMainMemory
���ڰ���Solaris��Linux���ڵĺܶ����ϵͳ���ܹ��������������ڴ��У��Ա�������̵Ľ�����ʹ��������ȷ���ص�ʵʱ���ԡ�
Ĭ������£��������DZ���ֹ�ġ�
�� [NDBD]StopOnError
���ִ���ʱ���ò���ָ����NDBD�������˳�����ִ���Զ�������
Ĭ������£����������ԡ�
�� [NDBD]Diskless
�ܹ���MySQL�صı�ָ��Ϊ�����̵ġ�������ζ�Ų����ڴ����϶Ա�ִ�м��������Ҳ���������־����������������������ڴ��С�ʹ�á����̡�����һ������ǣ����ֱ�������ᱣ���������Ҳ���ᱣ��������е��κμ�¼�����ǣ��������ڡ����̡�ģʽ��ʱ���ܹ������̼����������ndbd��
Ҫ�㣺�����Ի�ʹ�����������ڡ����̡�ģʽ�¡�
����������ʱ����ִ�б��ݲ�����������ʵ�ʱ��汸�����ݡ�
����Diskless������Ϊ��1����Y�������������ԡ�Ĭ������£���ֹ�����ԡ�
�� [NDBD]RestartOnErrorInsert
������������ʱ���ܷ��ʸ����ԣ���ִ����Ϊ������ɲ��ݵĴ����Ĺ����У����Բ������
Ĭ������£��������DZ���ֹ�ġ�
���Ƴ�ʱ��������ʹ��̷�ҳ
�ж�������ָ����ʱ�Լ������ݽڵ��и��ֶ�����ʱ�����IJ������������ʱֵ�Ժ���Ϊ��λָ�����κ��������������ʱָ����
�� [NDBD]TimeBetweenWatchDogCheck
Ϊ�˷�ֹ���߳���ijһ������������ѭ���������ˡ����Ź����߳���������̡߳��ò����Ժ���Ϊ��λָ���˼��֮���ʱ������������μ��֮������Ա�������ͬ��״̬�������������Ź����߳���ֹ��
��������Ŀ�ģ��ɷ���ظ��ĸò�����Ҳ���Զ�����е������ʺϱ���������Ҳ�����ڵ�ָ��������Ȼ�����������ɺ��١�
Ĭ�ϳ�ʱΪ4000���루4�룩��
�� [NDBD]StartPartialTimeout
�ò���ָ�����ڵ��ôس�ʼ���ӳ���֮ǰ���صȴ����д洢�ڵ���ֵ�ʱ�䡣�ó�ʱ�������ڷ�ֹ���ִ�������
Ĭ��ֵ��30000���루30�룩��0��ʾ����ʱ�����仰�����������нڵ������ʱ�Ż������ء�
�� [NDBD]StartPartitionedTimeout
�ȴ���StartPartialTimeout�������������������������Կ��ܴ��ڸ���״̬���ؽ��ȴ��ó�ʱʱ�������
Ĭ�ϳ�ʱΪ60000���루60�룩��
�� [NDBD]StartFailureTimeout
������ݽڵ��ڸò���ָ����ʱ����δ������������У��ڵ�������ʧ�ܡ�������ò�������Ϊ0����ʾ���������ݽڵ㳬ʱ��
Ĭ��ֵ��60000����(60�룩�����ڰ����������ݵ����ݽڵ㣬Ӧ���Ӹò��������磬���ڰ�����GB���ݵĴ洢�ڵ㣬Ϊ��ִ�нڵ�������������Ҫ10��15���ӣ���600000��1000000���룩��
�� [NDBD]HeartbeatIntervalDbDb
����ʧ�ܽڵ����Ҫ����֮һ��ʹ�á������������ò���ָ���������źŵķ���Ƶ�ʣ��Լ��������ǵ�Ƶ�ʡ������1���ڶ�ʧ�������������ڵ㽫������Ϊ��������ˣ�ͨ���������Ʒ��ֹ��ϵ����ʱ��������������ı���
Ĭ�ϵ��������Ϊ1500���루1.5�룩�����ô���ȸ��ĸò��������ڵ��ò����ı仯��ΧҲ���ù��������磬���ijһ�ڵ�ʹ����5000����ֵ�����۲����Ľڵ����1000���룬����Ȼ���ýڵ�ܿ�ͻᱻ����Ϊ�������ܹ������������ڼ���ĸò�����������Ӧ��С��
�� [NDBD]HeartbeatIntervalDbApi
ÿ�����ݽڵ�Ὣ�����źŷ��͵���MySQL��������SQL�ڵ㣩����ȷ�����ֽӴ������ijһMySQL������δ�ܼ�ʱ���������źţ�����������Ϊ����������������£��������ڽ��е����������ͷ�������Դ��SQL�ڵ㲻���������ӣ�ֱ������ǰ��MySQLʵ����ʼ�������л���Ϊֹ�����ڸ��жϵ�3�����о���HeartbeatIntervalDbDb��������ͬ��
Ĭ��ʱ����Ϊ1500���루1.5�룩����ͬ�����ݽڵ�֮�䣬�ü������������ͬ��������Ϊ��ÿ���洢�ڵ��������������������ݽڵ�۲���֮������MySQL��������
�� [NDBD]TimeBetweenLocalCheckpoints
�ò�����һ�����⣬��δָ�������µı��ؼ��ǰӦ�ȴ���ʱ�䣬�෴��������ȷ���ڳ�����Խ��ٸ��µĴ���δִ�б��ؼ���������ھ��нϸ߸����ʵĴ�������ڣ��ܿ�����ǰһ�����ؼ��������ɺ���������һ���µļ��������
��ǰһ�����ؼ���������������ִ��д�����Ĵ�С�����ӡ��ò���Ҳ��һ�����⣬ԭ����������ָ��Ϊ4�ֽ�����������2Ϊ�����Ķ�������ˣ�Ĭ��ֵ20��ʾ4MB (4 �� 220)д������21��ʾ8MB���������ƣ�ֱ����ͬ��8GBд���������ֵ31��
�������е�д����������һ�𡣽�TimeBetweenLocalCheckpoints����Ϊ6���С��ʾ���ؼ����������ͣ�ٵ�����ִ�У���صĹ��������ء�
�� [NDBD]TimeBetweenGlobalCheckpoints
�ύ����ʱ�������ύ�����о������ݵ����нڵ�����ڴ��С����ǣ�������־��¼������Ϊ�ύ���̵�һ����д����̡���ԭ�����ڣ���������̨�������������ϰ�ȫ���ύ����Ӧ��������ڹ��ڳ־��Եĺ�������
��һ������Ҫ�ķ����ǣ�Ӧȷ����ʹ���������£�����ȫ��������Ҳ�ܽ���ǡ���ش�����Ϊ��ȷ����㣬�ڸ���ʱ�����ڳ��ֵ�����������ᱻ�ŵ�ȫ�ּ��㣬�ɽ�����Ϊд����̵����ύ����ļ��ϡ����仰������Ϊ�ύ���̵���ɲ��֣���������ȫ�ּ����飻�Ժ������־��¼����д����̣�Ȼ�����������鰲ȫ���ύ���������м�����Ĵ����ϡ���
�ò���������ȫ�ּ������֮���ʱ������Ĭ��ֵΪ2000���롣 milliseconds.
�� [NDBD]TimeBetweenInactiveTransactionAbortCheck
���ڸò���ָ����ÿ��ʱ������ͨ�����ÿ������Ķ�ʱ����ִ�г�ʱ��������ˣ�����ò�������Ϊ1000���룬ÿ��1��ͻ��������м�顣
�ò�����Ĭ��ֵΪ1000���루1�룩��
�� [NDBD]TransactionInactiveTimeout
�������Ŀǰδִ���κβ�ѯ�����ǵȴ���һ�����û����룬�ò���ָ���˷�������֮ǰ�û��ܹ��ȴ����ʱ�䡣
�ò�����Ĭ��ֵ��0����ʱ����������Ҫȷ�����κ����������˹���ʱ������ݿ⣬Ӧ����������Ϊ��С��ֵ����λΪ���롣
�� [NDBD]TransactionDeadlockDetectionTimeout
���ڵ�ִ���漰����IJ�ѯʱ���ڼ���֮ǰ���ڵ㽫�ȴ����������ڵ�������Ӧ�������������ԭ�������Ի�Ӧ��
1. �ڵ㡰��������
2. ����������������
3. ������ִ�ж����Ľڵ㸺�ɹ��ء�
�ó�ʱ����ָ���˷�������֮ǰ������Э�����Ⱥ���һ�ڵ�ִ�в�ѯ��ʱ�䳤�̣��ò����ڽڵ�ʧ�ܴ�����������ⷽ��ʮ����Ҫ�����漰�����ͽڵ�ʧ�ܵ������£�����������õĹ��ߣ��ᵼ�²�����Ҫ����Ϊ��
Ĭ�ϵij�ʱֵΪ1200���루1.2�룩��
�� [NDBD]NoOfDiskPagesToDiskAfterRestartTUP
ִ�б��ؼ������ʱ����Ӧ���㷨�Ὣ��������ҳд����̡��������ɸò������������У��ܿ��ܻ�Դ�����������ʹ��̴������ظ�����Ϊ�˿���д���ٶȣ��ò���ָ����ÿ100�����д���������ҳ���ڱ������£�1������ҳ����Ϊ8KB������ò����ĵ�λ��ÿ��80KB����ˣ������NoOfDiskPagesToDiskAfterRestartTUP����Ϊ20����ô��ִ�б��ؼ�������ڼ䣬Ҫ��ÿ�������д��1.6MB�����ݡ���ֵ�����������ҳ��UNDO��־��¼д�룬Ҳ����˵���ò����ܴ������������ڴ��д�����ơ������������ҳ��UNDO��־��¼���������ɲ���NoOfDiskPagesToDiskAfterRestartACC�����ģ���������ҳ�ĸ�����Ϣ����μ�����IndexMemory����Ŀ����
�����֮���ò���ָ����ִ�б��ؼ���������ٶȣ�������NoOfFragmentLogFiles��DataMemory��IndexMemoryһ��ʹ�á�
Ĭ��ֵ��40��ÿ��3.2MB������ҳ����
�� [NDBD]NoOfDiskPagesToDiskAfterRestartACC
�ò���ʹ�õĵ�λ��NoOfDiskPagesToDiskAfterRestartTUP����ͬ��������ʽҲ���ƣ������Ƶ��Ǵ������ڴ���е�����ҳд���ٶȡ�
�ò�����Ĭ��ֵΪÿ��20�������ڴ�ҳ��1.6MBÿ�룩��
�� [NDBD]NoOfDiskPagesToDiskDuringRestartTUP
�ò����Ĺ�����ʽ������NoOfDiskPagesToDiskAfterRestartTUP��NoOfDiskPagesToDiskAfterRestartACC�������������ڵ�ʱ�ڽڵ���ִ�еı��ؼ��������Ч����Ϊ���нڵ���������ɲ��ݣ��ܻ�ִ�б��ؼ���������ڽڵ����������У��ܹ��Ա�����ʱ�������ٶ�ִ�д���д�������������Ϊ����ʱ�ڽڵ���ִ�еĻ�����١�
�ò����漰�������ڴ�д���ҳ��
Ĭ��ֵ��40��3.2MBÿ�룩��
�� [NDBD]NoOfDiskPagesToDiskDuringRestartACC
�ڽڵ������ı��ؼ���Σ����ܹ�д�뵽���̵������ڴ�ҳ����Ŀ���п��ơ�
��NoOfDiskPagesToDiskAfterRestartTUP��NoOfDiskPagesToDiskAfterRestartACCһ�����ò�����ֵ���õĵ�λҲ��ÿ100����д��8KB��80KB/�룩��
Ĭ��ֵ��20 (1.6MBÿ�룩��
�� [NDBD]ArbitrationTimeout
�ò���ָ�������ݽڵ�ȴ��ٲó�����ٲ���Ϣ�Ļ�Ӧ��ʱ�䡣��������˸�ʱ�䣬���ٶ������ѶϿ���
Ĭ��ֵ��1000���루1�룩��
�������־����
һЩ����ǰ�ı���ʱ�������Ӧ�����ò����Կ��á�ʹ����Щ���������û��ܹ��Խڵ����ʹ�õ���Դ���и���Ŀ��ƣ����ܸ�����Ҫ�������ֻ�������С��
����־��¼д�����ʱ����Щ�����������ļ�ϵͳ��ǰ�ˡ�����ڵ�����������ģʽ�£���ô���Խ���Щ��������Ϊ���ǵ���Сֵ��������ɸ���Ӱ�죬������Ϊ������д������NDB�洢������ļ�ϵͳ��ȡ������ġ�
�� [NDBD]UndoIndexBuffer
�û������ڱ��ؼ������ִ���ڼ䡣NDB�洢����������һ�ָֻ��������÷��������ڼ���һ�����Լ�������REDO��־ֵ�ϡ�Ϊ���ڲ���������ϵͳ��д����������»��һ�µļ��㣬��ִ�б��ؼ��������ͬʱ����ִ��UNDO��־������UNDO��־����ÿ�����ڵ�����ƫ���ϴ����ġ����ڱ�ȫ�����������ڴ��У����Ż��ǿ��ܵġ�
UNDO������������������ϣ�����ϵĸ��¡������ɾ�������ᵼ�¹�ϣ�������������У�NDB�洢���潫ӳ�������������仯��UNDO��־��¼д������ҳ���Ա�����ϵͳ����ʱ������Щ�仯�������ܼ�¼�������ؼ������ʱ��ÿ��ƫ�̵����в��������
��ȡ�����ܹ���������λ�������¹�ϣ������Ŀ�еı��⡣��������ҳд���㷨����������ȷ����Щ��������ҪUNDO��־��
�û����Ĭ�ϴ�СΪ2MB����СֵΪ1MB�����ڴ����Ӧ�ã���Сֵ���㹻������ִ�м���ͣ�����������ɾ��������������������ʹ�������Ӧ�ó������б�Ҫ����û��塣����û����С��NDB�洢����ᷢ���������677������UNDO������ء���
�� [NDBD]UndoDataBuffer
UNDO���ݻ����������UNDO�����������ͬ����֮ͬ�����ڣ��������������ڴ��϶����������ڴ��ϡ����ڲ��롢ɾ�����£��û�������Ƭ�εı��ؼ����ʹ�õġ�
����UNDO��־��Ŀ����������¼���������Ӷ����û��������֮��Ӧ�������ڴ滺�壬Ĭ��ֵΪ16MB��
����ijЩӦ�ó����ڴ���ܹ�������������£��ɽ�������ֵ����СΪ1MB��
��Ҫ���Ӹû�������ʮ�ֺ��������ȷʵ���ⷽ���Ҫ�Ϻõķ�ʽ�ǣ��������Ƿ���ʵ�ʴ������ݿ���»�������ĸ��ɡ����ȱ���㹻�Ĵ��̿ռ䣬��ʹ���Ӹû���Ĵ�СҲ���ܽ�����⡣
����û����С����á�ӵ����������NDB�洢���潫�����������891������UNDO������ء���
�� [NDBD]RedoBuffer
���еĸ��»Ҳ��Ҫ����¼����־�С�ʹ��������־����ϵͳ����ʱ���ܹ�����������¡�NDB�ָ��㷨�����ˡ�ģ�������ݼ����UNDO��־��Ȼ��ʹ��REDO��־�������б仯ֱ������ָ��㡣
�û����Ĭ�ϴ�С��8MB����СֵΪ1MB��
����û����С��NDB�洢���潫�����������1221��REDO��־�����������
�ڹ����صĹ����У�Ӧ�ܿ���Ϊ�����¼����ͷ����������װ�õ���־��Ϣ����Ŀ�����ʮ����Ҫ����16�ֿ��ܵ��¼����𣨱�Ŵ�0��15��������������¼������¼�ͨ����������Ϊ15����ô������е������¼�������ᱻ�����������װ�ã������������Ϊ0����ʾ�ڸ�����е�û���¼����档
Ĭ������£����Ὣ������Ϣ�����������װ�ã�������¼�ͨ������Ĭ��Ϊ0����������ԭ�����ڣ���Щ��ϢҲ�ᱻ�����������������Ĵ���־��
���ڹ����ͻ��ˣ�Ҳ���������Ƶļ�������ȷ���ڴ���־�м�¼��Щ������¼���
�� [NDBD]LogLevelStartup
ͨ���������ڽ����������������ɵ��¼���
Ĭ�ϼ���Ϊ1.
�� [NDBD]LogLevelShutdown
ͨ������������Ϊ�ڵ�ǡ���رս�����ɲ��ֶ����ɵ��¼���
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelStatistic
ͨ����������ͳ���¼�������������ȡ������������Ŀ��������Ŀ���뻺��ʹ���йص���Ϣ�ȡ�
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelCheckpoint
ͨ�����������ɱ��غ�ȫ�ּ���������ɵ��¼���
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelNodeRestart
ͨ�����������ڽڵ��������������ɵ��¼���
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelConnection
ͨ�����������ɴؽڵ����������ɵ��¼���
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelError
ͨ���������������������ڵĴ���;������ɵ��¼���������ᵼ���κνڵ�ʧ�ܣ�����ֵ��ͨ����
Ĭ�ϼ���Ϊ0.
�� [NDBD]LogLevelInfo
ͨ����������Ϊ�ص�һ��״̬��Ϣ�����ɵ��¼���
Ĭ�ϼ���Ϊ0.
���ݲ���
�������۵IJ��������������߱���ִ���йص��ڴ滺�弯��
�� [NDBD]BackupDataBufferSize
�ڴ������ݵĹ����У�Ϊ�˽����ݷ��͵����̣���ʹ������塣�������ݻ������������ɨ��ڵ�ı�����¼�����ݡ�һ�����û�����䵽��ָ����ˮƽBackupWriteSize����μ�����Ľ��ܣ����ͻὫҳ���������̡��ڽ�ҳд����̵�ͬʱ�����ݽ����ܹ��������û��壬ֱ����ռ�������Ϊֹ�����ָ����ʱ�����ݽ��̽���ͣɨ�裬ֱ��һЩ����д�������ɲ��ͷ����ڴ�Ϊֹ��Ȼ��ɨ�������
�ò�����Ĭ��ֵΪ2MB��
�� [NDBD]BackupLogBufferSize
������־������ݵĽ�ɫ�����ڱ������ݻ��壬��֮ͬ�����ڣ����������ɱ���ִ���ڼ���е����б�д�����־����ͬ��ԭ��Ҳ�����ڱ������ݻ��������µ�ҳд�룬��֮ͬ�����ڣ���������־������û�ж���ռ�ʱ�����ݽ�ʧ�ܡ����ڸ�ԭ������־����Ĵ�СӦ���Դ���ִ�б���ʱ�����ĸ��ء�
�ò�����Ĭ��ֵ���ڴ����Ӧ�ó�������ʵ��ġ���ʵ�ϣ�����ʧ�ܵ�ԭ�����������Ϊ����д���ٶȲ����������DZ�����־������������û��ΪӦ�ó��������д�������ô�����ϵͳ���غܿ�����ִ������IJ�����
��ð�ǡ���ķ�ʽ���ôأ�ʹ�ô�������Ϊƿ�������Ǵ��̻��������ӡ�
Ĭ��ֵ��2MB��
�� [NDBD]BackupMemory
�ò�����BackupDataBufferSize��BackupLogBufferSize֮�͡�
Ĭ��ֵ��2MB + 2MB = 4MB��
�� [NDBD]BackupWriteSize
�ò���ָ�����ɱ�����־����ͱ������ݻ���д����̵���Ϣ��С��
Ĭ��ֵ��32KB.
�� [MYSQLD]Id
��ֵ�����ڵ�ĵ�ַ�������еĴ��ڲ���Ϣʹ�ã��������ǽ���1��63֮����������ڴ��ڣ�ÿ���ؽڵ������Ψһ��ID��
�� [MYSQLD]ExecuteOnComputer
�����õ����������ļ���[COMPUTER]���ֶ�����������������֮һ��
�� [MYSQLD]ArbitrationRank
�ò������ڶ������Ϊ�ٲó���Ľڵ㡣MGM�ڵ��SQL�ڵ���ܳ�Ϊ�ٲó������ֵΪ0�����������Ľڵ���Զ���������ٲó������ֵΪ1�����������Ľڵ��ڳ�Ϊ�ٲó�������иߵ����ȼ������ֵΪ2�����������Ľڵ��ڳ�Ϊ�ٲó�������е͵����ȼ��������������ã�ʹ�ù�����������Ϊ�ٲó�������ArbitrationRank����Ϊ1��Ĭ�ϣ�����������SQL�ڵ��ArbitrationRank����Ϊ0��
�� [MYSQLD]ArbitrationDelay
������ò�������Ϊ��0��Ĭ��ֵ�����������ֵ����ʾ�ٲó�����ٲ��������Ӧ�����ӳ��趨�ĺ�������ͨ������Ҫ���ĸ�ֵ��
�� [MYSQLD]BatchByteSize
����ת��Ϊȫ��ɨ���������ķ�Χɨ��IJ�ѯ��Ҫ����������ܣ���Ҫ������ǡ���Ĵ�С��ȡ��¼���ܹ��Լ�¼��Ϊ��λ��BatchSize�����ֽ�Ϊ��λ��BatchByteSize������ǡ���Ĵ�С��ʵ�ʵ�����С��������������
��ѯ��ִ���ٶȿ��ܻ����40���ı仯���������ȡ���ڸò��������á���δ���İ汾�У�MySQL�����������ݲ�ѯ����ǡ��������������С��صIJ�����
�ò������ֽ�Ϊ��λ��Ĭ��ֵ��32KB��
�� [MYSQLD]BatchSize
�ò����Լ�¼��Ϊ��λ��Ĭ��ֵ��64�����ֵΪ992��
�� [MYSQLD]MaxScanBatchSize
����Сָ���ǴӸ����ݽڵ㷢�͵�ÿ�����ݵĴ�С�������ɨ������Բ��з�ʽִ�еģ�Ŀ����Ϊ�˷�ֹMySQL�������յ������ڶ�ڵ�Ĺ������ݣ��ò��������нڵ��ϵ��ܵ�����С���������ơ�
�ò�����Ĭ��ֵΪ256KB��������СΪ16MB��
17.4.4.7. MySQL��TCP/IP����
��MySQL���У�TCP/IP�����ڽ������ӵ�Ĭ�ϴ���Э�顣��������²���Ҫ�������ӣ�������Ϊ�������Զ��������ݽڵ�䡢���ݽڵ�������MySQL�������ڵ㡢�Լ����ݽڵ������������֮������ӣ����ڸù�������⣬����μ�17.4.4.8�ڣ���ʹ��ֱ�����ӵ�MySQL��TCP/IP���ӡ�)��
������㸲��Ĭ�ϵ����Ӳ���������Ҫ�������ӡ�����������£�������Ҫ����NodeId1��NodeId2���Լ�������ĵIJ�����
ͨ����[TCP DEFAULT]���ֽ������ã�Ҳ�ܸ�����Щ������Ĭ��ֵ��
�� [TCP]NodeId1 , [TCP]NodeId2
Ҫ��ȷ�������ڵ�֮������ӣ���Ҫ�������ļ��ġ�TCP���������ṩÿ���ڵ��ID��
�� [TCP]SendBufferMemory
�������ϵͳ������������֮ǰ��TCP���������û������������е���Ϣ�����û���ﵽ64KBʱ�������������ݣ�ִ����һ����Ϣѭ����Ҳ��������Щ���ݡ�Ϊ�˴�����ʱ���������Ҳ�ܶ���һ���ϴ�ķ��ͻ��塣���ͻ����Ĭ��ֵ��256KB��
�� [TCP]SendSignalId
Ϊ���ܹ���ɨ�ֲ�ʽ��Ϣͼ����Ҫȷ��ÿ����Ϣ�����ò�������Ϊ��Y��ʱ����ͨ�����紫����ϢID��Ĭ������½�ֹ�����ԡ�
�� [TCP]Checksum
�ò���Ҳ��һ������������Y/N��1/0����Ĭ��������ǽ�ֹ�ġ������˸ò���ʱ���ڽ�������Ϣ���ڷ��ͻ���֮ǰ����Ϊ���в�������У��͡�ʹ�ø����ԣ�����Ϣ�Ⱥ��ڷ��ͻ�����ʱ������ȷ����Ϣ������Ҳ��ȷ����Ϣ���ᱻ��������ƻ���
�� [TCP]PortNumber
���ѹ�ʱ����ǰ���ò���ָ�������ڼ������������ڵ�����ӵĶ˿ںš���Ӧ��ʹ�ø²�����
�� [TCP]ReceiveBufferMemory
ָ���˴�TCP/IP���ֽ�������ʱ��ʹ�õĻ����С����������Ҫ���ĸò�����Ĭ��ֵ��Ĭ��ֵΪ64KB��������������ʡ�ڴ棬Ҳ�ܸ�������
�������ʾ���У��ٶ��ؾ�������4̨������1̨���ڹ�����������һ̨����SQL�ڵ㣬��̨�������ݽڵ㡣��Ϊ���壬��λ��LAN��172.23.72.*�����ڡ�����ͨ�������������⣬�������ݽڵ�ʹ�ñ��Ľ������ֱ����������ʹ�÷�Χ��1.1.0.*��IP��ַ�˴˼�ֱ��ͨ�ţ�������ʾ��
# Management Server
[NDB_MGMD]
Id=1
HostName=172.23.72.20
# SQL Node
[MYSQLD]
Id=2
HostName=172.23.72.21
# Data Nodes
[NDBD]
Id=3
HostName=172.23.72.22
[NDBD]
Id=4
HostName=172.23.72.23
# TCP/IP Connections
[TCP]
NodeId1=3
NodeId2=4
HostName1=1.1.0.1
HostName2=1.1.0.2
ʹ�����ݽڵ���ֱ�������ܹ����ƴص�����Ч�ʣ�ʹ�ø÷�ʽ�����ݽڵ����ƹ���̫���豸���罻������Hub��·�����ȣ��Ӷ������˴صĵȴ�ʱ�䡣ע�⣬�����������ϵ����ݽڵ㣬Ҫ������������ֱ�����ӵ��ŵ㣬��ҪΪ�����ݽڵ㽨������ͬ�ڵ����ڵ��������ݽڵ���ֱ�����ӡ�
17.4.4.9. MySQL�ع����ڴ�����
ע�ͣ�SHM֧����Ӧ����Ϊ�����Եġ�
�� [SHM]NodeId1, [SHM]NodeId2
Ҫ��ȷ�������ڵ�֮������ӣ���ҪΪÿ���ڵ��ṩ�ڵ�ID��NodeId1��NodeId2��
�� [SHM]ShmKey
���ù����ڴ��ʱ���ڵ�ID����Ψһ��ȷ��ͨ�����õĹ����ڴ�Ρ�����������ʾ��û��Ĭ��ֵ��
�� [SHM]ShmSize
ÿ��SHM���Ӿ���һ�������ڴ�Σ����ͷ����ڵ�֮�����Ϣ���ڸô�����ȡ���Ӹô���ȡ������Ϣ��gai �����ڴ�εĴ�С��ShmSize���塣Ĭ��ֵ��1MB��
�� [SHM]SendSignalId
Ϊ�˻�ɨ�ֲ�ʽ��Ϣ��·������ҪΪÿ����Ϣ�ṩΨһ��ID��������ò�������Ϊ��Y����Ҳ���������ϴ���������ϢID��Ĭ������£��������ǽ�ֹ�ġ�
�� [SHM]Checksum
�ò���Ҳ��һ��Y/N������Ĭ������´��ڽ�ֹ״̬����������ò������ڽ�������Ϣ���ڷ��ͻ���֮ǰ����Ϊ������Ϣ����У��͡�
ʹ�ø����ԣ�����Ϣ�Ⱥ��ڷ��ͻ�����ʱ���ܷ�ֹ��Ϣ�����⣬�����������ڴ�������м�������ݡ�
17.4.4.10. MySQL��SCI��������
���⣬SCIҪ��ר��Ӳ����
ǿ�ҽ��飬��ӦΪndbd����֮���ͨ��ʹ��SVI��������ע�⣬ʹ��SCI��������ζ��ndbd��������ֹͣ����ˣ���Ӧ�ھ�����������ר��ndbd����ʹ�õ�CPU�Ļ�����ʹ��SCI��������ÿ��ndbd��������Ӧ��1��CPU�����ٻ�Ӧ��1��CPU���ڴ�������ϵͳ�Ļ��
�� [SCI]NodeId1, [SCI]NodeId2
Ϊ��ȷ�������ڵ�֮������ӣ���ҪΪÿ���ڵ��ṩ�ڵ�ID��NodeId1��NodeId2��
�� [SCI]Host1SciId0
������ȷ����1���ؽڵ��ϵ�SCI�ڵ�ID����NodeId1ȷ������
�� [SCI]Host1SciId1
�ܹ�Ϊ����SCI����Ĺ����л�����SCI�������������鿨Ӧʹ�ýڵ�֮��IJ�ͬ���硣������ȷ���ڵ�ID���Լ��ڵ�1���ڵ���ʹ�õĵ�2��SCI����
�� [SCI]Host2SciId0
������ȷ����2���ؽڵ��ϵ�SCI�ڵ�ID����NodeId2ȷ������
�� [SCI]Host2SciId1
ʹ������SCI�����ṩ�����л�����ʱ���ò�������ȷ�����ڵ�2���ڵ���ʹ�õĵ�2��SCI����
�� [SCI]SharedBufferSize
ÿ��SCI����������1���������ڵ��ͨ�ŵĹ����ڴ�Ρ��ɽ��ù����ڴ������ΪĬ�ϵ�1 MB��������Ӧ�Դ����Ӧ�ó������ʹ�ý�С��ֵ����ִ�д������в������ʱ����������⣬�繲�������С�����ᵼ��ndbd���̱�����
�� [SCI]SendLimit
SCIý��ǰ���С�������ڱ�����Ϣ����ͨ��SCI���紫��������Ϣǰ���Ὣ���DZ����ڸû����ڡ�����Ĭ��ֵΪ8kB���������ǵĻ�����64KBʱ������ã���16kB����������������ʹ����8KB�кô����ô�Ҳ����
�� [SCI]SendSignalId
Ϊ�˸��ٷֲ�ʽ��Ϣ����ҪΨһ��ȷ��ÿ����Ϣ�����ò�������Ϊ��Y��ʱ�������������ϴ�����ϢID��Ĭ������½�ֹ�����ԡ�
�� [SCI]Checksum
T�ò���Ҳ��һ�ֲ���ֵ��Ĭ������£��ò����DZ���ֹ�ġ�������Checksum��У��ͣ�ʱ���ڽ�������Ϣ���ڷ��ͻ���֮ǰ����Ϊ���в�������У��͡�ʹ�ø����ԣ�����Ϣ�Ⱥ��ڷ��ͻ�����ʱ������ȷ����Ϣ���������⣬�����������ڴ�������м�������ݡ�
17.5. MySQL���еĽ��̹���
mysqld�Ǵ�ͳ��MySQL���������̡�Ҫ����MySQL��һ��ʹ�ã���������mysqldӦ֧��NDB�ش洢���棬������Ԥ�����-max�����ư汾��������http://dev.mysql.com/downloads/��
��ʹ���ø÷�ʽ������mysqld�����ư汾����Ĭ������£�NDB�ش洢�����Դ��ڽ�ֹ״̬��Ҫ������NDB�ش洢���棬��ʹ�����ֿ��ܵ�ѡ��֮һ��
�� ����mysqldʱ��������ndbcluster����������ѡ�
�� ��my.cnf�ļ���[mysqld]���ֲ������ndbcluster��1�����ݡ�
��֤���еķ������Ƿ�������NDB�ش洢����ļ����ǣ���MySQL��������mysql���з�������SHOW ENGINES�����г�NDBCLUSTER������Ӧ�ܿ���ֵYES������ڸ����Ͽ���NO�����������δ��ʾ���У����������е���δ����NDB���ܵ�MySQl�汾������ڸ����Ͽ���DISABLED����������������ַ���֮һ��������
Ϊ�˶�ȡ���������ݣ�MySQL������������Ҫ3����Ϣ��
�� MySQL�������Լ��Ĵؽڵ�ID��
�� ������������MGM�ڵ㣩����������IP��ַ��
�� ����������������Ķ˿ڡ�
�ڵ�ID�ɶ�̬���䣬��˲�һ����Ҫ��ȷָ�����ǡ�
mysqld����ndb-connectstring����ָ�������ַ���������������mysqldʱ����������ָ����������my.cnf�ļ���ָ���������ַ���������������IP��ַ���Լ��ܹ����ֹ����������Ķ˿ڡ�
�������ʾ���У�ndb_mgmd.mysql.com�ǹ������������ڵ������������������ڶ˿�1186�ϼ�������Ϣ��
shell> mysqld --ndb-connectstring=ndb_mgmd.mysql.com:1186
���������ַ����ĸ�����Ϣ����μ�17.4.4.2�ڣ���MySQL�������ַ�������
��������Ϣ��MySQL����������Ϊ���е���ȫ�����ߡ�����ʱ������Ҳ�������ڸ÷�ʽ�µ�mysqld���̳�ΪSQL�ڵ㣩��������ȫ�˽����еĴ����ݽڵ��Լ����ǵ�״̬�����ܽ������������ݽڵ�����ӡ������������£����ܽ��κ����ݽڵ���������Э���������ܷ������ݽڵ���ִ�ж�ȡ���²�����
ndbd��ʹ��NDB�ش洢���洦�������������ݵĽ��̡�ͨ���ý��̣��洢�ڵ��ܹ�ʵ�ֲַ�ʽ���������ڵ�ָ����Դ��̵ļ�����������߱��ݣ��Լ���ص�����
��MySQL���У�һ��ndbd�����ܹ���ͬ�������ݡ���Щ���̿�������ͬ�ļ��������������ִ�У�Ҳ���ڲ�ͬ�ļ������ִ�С����ݽڵ�ʹ�����֮���ͨ������ȫ�����õġ�
Ndbd������һ����־�ļ�����Щ�ļ�λ���������ļ���DataDirָ����Ŀ¼�¡������г�����Щ��־�ļ���ע�⣬node_id�����ڵ��ΨһID�����磬ndb_2_error.log���ɽڵ�IDΪ2�Ĵ洢�ڵ����ɵĴ�����־��
�� ndb_node_id_error.log�ǰ���������ndbd���������������б�����¼���ļ������ļ��е�ÿ����¼������1����Ҫ�Ĵ����ַ������Լ��Ըñ��������ļ������á����ļ��ĵ�����Ŀ��������������ƣ�
�� Date/Time: Saturday 30 July 2004 - 00:20:01
�� Type of error: error
�� Message: Internal program error (failed ndbrequire)
�� Fault ID: 2341
�� Problem data: DbtupFixAlloc.cpp
�� Object of reference: DBTUP (Line: 173)
�� ProgramName: NDB Kernel
�� ProcessID: 14909
�� TraceFile: ndb_2_trace.log.2
�� ***EOM***
ע�ͣ����ס��������־�ļ��е����1����Ŀ������Ȼ�����µģ�Ҳ��̫���ܣ���������Ҫ��������־�е���Ŀ���ǰ�ʱ��˳�����еģ�������ndb_node_id_trace.log.next����μ�����Ľ��ܣ��ж���ĸ����ļ���˳���Ӧ����ˣ�������־��Ŀ�ǰ�ѭ����ʽ������˳��ʽ���ǵġ�
�� ndb_node_id_trace.log.trace_id��ȷ�����˴������֮ʱ����������ĸ����ļ�������Ϣ��MySQL�ؿ����Ŷӽ��з���ʱ���а�����
�ܹ��Ը��Ǿ��ļ�֮ǰ�����ĸ����ļ�����Ŀ�������á�trace_id��Ϊÿ�������ĸ����ļ����ӵı�š�
�� ndb_node_id_trace.log.next�Ǽ�¼��Ҫָ������һ�������ļ���ŵ��ļ���
�� ndb_node_id_out.log�ǰ���ndbd���̵��κ�����������ļ���������ndbd����Ϊ�˿ڼල����ʱ�Żᴴ�����ļ���
�� ndb_node_id.pid�ǰ�������ʱ��Ϊ�˿ڼල�����ndbd���̵Ľ���ID���ļ����������������ļ������ã��Է�ֹ����������ͬID�Ľڵ㡣
�� ndb_node_id_signal.log�ǽ���ndbd������ʹ�õ��ļ������ܸ���ndbd���������е���վ����վ���ڲ���Ϣ���Լ����ǵ����ݡ�
���鲻Ҫʹ��ͨ��NFS��װ��Ŀ¼��������Ϊ��ijЩ����£����pid-file�ϵ�����������Ч����ʹ��������ֹ��Ҳ��������⡣
����ndbdʱ��������Ҫָ���������������������Լ������Ķ˿ںš���Ϊ��ѡ��ʽ��Ҳ����ָ�����̽�ʹ�õĽڵ�ID��
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
�����ⷽ��Ķ�����Ϣ����μ�17.4.4.2�ڣ���MySQL�������ַ�������
����ndbdʱ����ʵ���Ͻ��������ֽ��̡���1�ֽ��̳�Ϊ��angel process������ʹ���̣�������Ψһ�����Ƿ���ִ�н����ں�ʱ��ɣ�Ȼ������ndbd���̣�������˸����õĻ�������ˣ���������ʹ��Unix��kill����ɱ��ndbd���̣�����Ҫɱ�����������̡���ֹndbd���̵ĸ�ǡ��������ʹ�ù����ͻ��ˣ���ͨ���ù����ͻ���ֹͣ���̡�
ִ�н��̲�����1���̣߳����ڶ�ȡ��д���ɨ�����ݣ��Լ��������������߳����첽ʵʩ�ģ��Ա��ܷ���ش�������ǧ�ƵIJ���������⣬���Ź��̸߳���ලִ���̣߳���ȷ��ִ���̲߳�����������ѭ�����̳߳ظ������ļ�I/O��ÿ���߳̾��ܴ���һ�����ļ�����Щ�߳�Ҳ�ܱ�ndbd�����еĴ������������������ӡ���ִ�а����������ڵĴ���������ϵͳ�У����������ndbd������ռ��2��CPU������ӵ�ж�CPU�Ļ���������ʹ�����ڲ�ͬ�ڵ��������ndbd���̡�
����������������һ�ֽ��̣�����ȡ�������ļ�����������Ϣ��������������������Ϣ�Ľڵ㡣��������ά���ػ����־�������ͻ����ܹ����ӵ������������������ص�״̬��
��������������ʱ������һ����Ҫָ�������ַ��������ǣ����ʹ����1�����ϵĹ�����������Ӧ�ṩ�����ַ��������Ҵ��е�ÿ���ڵ�Ӧ��ȷָ���Լ��Ľڵ�ID��
�����ļ�����ndb_mgmd��������Ŀ¼�´�����ʹ�õģ����ᱻ���������ļ���ָ����DataDir�С���������б��У�node_id��Ψһ�Խڵ�ID��
�� config.ini����Ϊ����Ĵص������ļ������ļ����û��������ɹ�����������ȡ����17.4�ڣ���MySQL�ص����á��У����������ø��ļ��ķ�����
�� ndb_node_id_cluster.log�Ǵ��¼���־�ļ��������¼������Ӱ����������������������ɣ��ڵ������¼����ڵ���ϣ��Լ��ڴ�ʹ��ˮƽ�����ڴ��¼��������б�����������μ�17.6�ڣ���MySQL�صĹ�������
������־�Ĵ�С�ﵽ1MBʱ���ļ�����������Ϊndb_node_id_cluster.log.seq_id������seq_id�Ǵ���־�ļ������кţ����磬������1��2��3�Ѵ��ڣ���һ����־�ļ�����4��������
�� ndb_node_id_out.log�ǽ����������������˿ڼල����ʱ����stdout��stderr���ļ���
�� ndb_node_id.pid�ǽ����������������˿ڼල����ʱ��ʹ�õ�PID�ļ���
���ڴص����У�ʵ���ϲ���Ҫ�����ͻ��˵Ľ��̡����ֵ�������ṩ��һ�����������������ڼ��ص�״̬���������ݡ���ִ�������������ܡ������ͻ���ʹ��C API�����ʹ��������������û�Ҳ��ʹ��C API������ר�õĹ���������ִ����������������ndb_mgmִ�е����ơ�
���������ͻ���ʱ����Ҫ�ṩ�������������������Ͷ˿ںţ���������ʾ��Ĭ��ֵ��localhost��1186��
shell> ndb_mgm localhost 1186
����ʹ��ndb_mgm�ĸ�����Ϣ����μ�17.5.5.4�ڣ���ndb_mgm������ѡ������17.6.2�ڣ��������ͻ��ˡ��е�������
����MySQL�صĿ�ִ���ļ�����mysqld����ʹ������ѡ�����MySQL�ذ汾���û�Ӧע�⣬��Щѡ����е�һЩ��MySQL 4.1���е���������ı䣬Ϊ���DZ�������֮���һ���ԣ��Լ���mysqld��һ���ԡ�����ʹ��-?�������鿴֧�ֵ�ѡ���б���
�� -?, --usage, --help
���������嵥���Լ���������ѡ���������
�� -V, --version
����ndbd���̵İ汾�š��ð汾����MySQL�صİ汾�š��汾����һ�������ã�������Ϊ�������еİ汾����һ��ʹ�ã�����������ʱ��MySQL�ؽ��̽���֤�������ļ��İ汾�Ƿ�����ͬһ���ڹ��档ִ��MySQL�ص���������ʱ����Ҳ����Ҫ����μ�MySQL�ص�������������
�� -c connect_string, --connect-string
connect_string��Ϊ����ѡ���������������������������ַ�����
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
�� --debug[=options]
��ѡ��������ھ��е��Թ��ܵİ汾��ʹ�������ܹ�����mysqld������ͬ�ķ�ʽ�������Ե��Ե��õ������
�� -e, --execute
ʹ�������ܹ���ϵͳshell�����������ִ�г����磺
shell> ndb_mgm -e show
��
shell> ndb_mgm --execute="SHOW"
����
NDB> SHOW;
�������ڡ�-e��ѡ����mysql�����пͻ���һ�����ķ�ʽ����μ�4.3.1�ڣ�������������ʹ��ѡ���
�� --ndbcluster
��������ư汾������NDB�ش洢�����֧�֣���ʹ�ø�ѡ��Ƕ�NDB�ش洢���棨���ΪNDB�洢���棩��Ĭ�Ͻ�ֹ���á�ʹ��MySQL��ʱ��NDB�ش洢�����DZ�Ҫ�ġ�
�� --skip-ndbcluster
��ֹNDB�ش洢���档���ڰ����ù��ܵĶ����ư汾����Ĭ������£��ù����DZ���ֹ�ģ����仰����NDB�ش洢���洦�ڽ�ֹ״̬��ֱ��ʹ������ndbcluster��ѡ�������Ϊֹ������������ķ�����֧��NDB�ش洢����ʱ������ʹ�ø�ѡ�
�� --ndb-connectstring=connect_string
ʹ��NDB�洢����ʱ��ͨ�����ø�ѡ��ܹ�ָ��������������ݵĹ�����������
����ijЩ����ѡ��ĸ�����Ϣ����μ�17.5.5�ڣ�������MySQL�ؽ��̵�����ѡ���
�� -d, --daemon
֪ͨndbd��Ϊdaemon���˿ڼල������ִ�У�Ĭ����Ϊ����
�� --nodaemon
ָ��ndbd������Ϊdaemon���˿ڼල����������������ndbd�Լ�ϣ��������ض�����Ļʱ���������á�
�� --initial
֪ͨndbdִ�г�ʼ����������ʼ��������ɾ����ǰndbdʵ��Ϊ�ָ�Ŀ�Ĵ������κ��ļ������������´����ָ�����־�ļ���ע�⣬��ijЩ����ϵͳ�ϣ��ý��̿��ܻ�ռ�ýϳ���ʱ�䡣
�����״�����ndbd����ʱ��Ӧʹ����initial������������Ϊ����ɾ�����ļ�ϵͳ�������ļ������ٴδ������е�REDO��־�ļ����ù�����������£�
o ִ����Щ������ļ����ݵ���������ʱ��
o ���µ�ndbd�汾�����ڵ�ʱ��
o ����ij��ԭ�ڵ�������ϵͳ��������ʧ��ʱ������ֶΡ������������£���ע�⣬���������ļ���������ʹ�øýڵ����ָ����ݡ�
��ѡ�Ӱ����Щ�ѱ���Ӱ��ڵ㴴���ı����ļ���
�� --nostart
ָʾndbd���Զ�������ʹ�ø�ѡ��ʱ��ndbd���ӵ��������������ӹ�����������ȡ�������ݣ�����ʼ��ͨ�Ŷ����ǣ��ڹ����������ر�Ҫ��֮ǰ��������ʵ������ִ�����档ͨ��������ͻ��˷���ǡ�����������ɸ�����
����ijЩ����ѡ��ĸ�����Ϣ����μ�17.5.5�ڣ�������MySQL�ؽ��̵�����ѡ���
�� -f filename, --config-file=filename, (OBSOLETE): -c filename
֪ͨ����������Ӧʹ���ĸ��ļ���Ϊ�������ļ�������ָ����ѡ��ļ���Ĭ��Ϊconfig.ini��ע�⣬��-c����ݷ�ʽ�ѹ�ʱ����Ӧ���µİ�װʵ����ʹ������
�� -d, --daemon
ָʾndb_mgmd��Ϊ�˿ڼල��������������Ĭ����Ϊ��
�� --nodaemon
ָʾ��������������Ϊ�˿ڼල����������
����ijЩ����ѡ��ĸ�����Ϣ����μ�17.5.5�ڣ�������MySQL�ؽ��̵�����ѡ���
�� [host_name [port_num]]
Ҫ�����������ͻ��ˣ���Ҫָ���������������ڵ�λ�ã���ָ���������Ͷ˿ڡ�Ĭ�ϵ���������localhost��Ĭ�϶˿���1186��
�� --try-reconnect=number
�������������������ӶϿ���ÿ��5�룬�ڵ㽫�����ٴ����ӵ�������������ֱ���ɹ���ʹ�ø�ѡ��ܹ������Ե�����������numberָ����ֵ�����������ƺ��������Բ�ͨ������
����MySQL���漰�ڶ��������������ú�����MySQL�ء�������μ�17.4�ڣ���MySQL�ص����á���17.5�ڣ���MySQL���еĽ��̹�������
���������MySQL�صĹ������ˡ�
�����ֻ�������MySQL�صĻ�����������1�ַ����ǣ�ʹ���ڹ����ͻ���������������˿ɼ��ص�״̬��������־����������ֹͣ���ݣ��Լ�������ֹͣ�ڵ㡣���ڵ�2�ַ�������Ҫ�о�����������DataDirĿ¼�´���־�ļ�ndb_node_id_cluster.log�����ݡ���node_id�������ѱ���¼�Ľڵ��ΨһID��������־������ndbd���ɵ��¼����档Ҳ�ܽ�����־��Ŀ���͵�Unix��ϵͳ��־�С�
���ڽ�����������ʱ�漰�IJ��衣
�����ֲ�ͬ���������ͺ�ģʽ������������
�� �״������������нڵ�����ɾ����ļ�ϵͳһ�������ء�����dz������״�������ʱ������ʹ�á�--initial��ѡ��������ʱ��
�� ϵͳ����������������ȡ���������ݽڵ��е����ݡ����������������£�ʹ�����ر��˴أ���ϣ���Ӵص�ֹͣ��ָ��ز���ʱ��
�� �ڵ������������ڴ����е�ͬʱ�ؽڵ������������
�� �״νڵ���������ڵ��������ƣ�������ڽ��ٴγ�ʼ���ڵ㣬����ɾ����ļ�ϵͳһ��������
����֮ǰ�������ÿ���ڵ���г�ʼ��������ndbd���̣���������������裺
1. ��ȡ�ڵ�ID��
2. ��ȡ�������ݡ�
3. Ϊ�ڵ���ͨ�ŷ���˿ڡ�
4. ���ݴ������ļ���õ����÷����ڴ档
һ������˶Ը��ڵ�ij�ʼ����������������������̡��ڸý����У��ؽ����������Σ�
�� ��0
�������ļ�ϵͳ������ʹ�á�--initial��ѡ��������ʱ���Ż���֡�
�� ��1
���������ӣ������ڵ���ͨ�š������ء����������ơ�
�� ��2
ѡ���ٲó���ڵ㡣
�������ϵͳ�����Σ��ؽ�ȷ������Ŀɻָ�ȫ�ּ��㡣
�� ��3
�ýΰ����ڶ��ڲ��ر����ij�ʼ����
�� ��4
���ڳ�ʼ�������ʼ�ڵ�������������redo��־�ļ��������ļ�����Ŀ����NoOfFragmentLogFiles��
����ϵͳ������
o ��ȡ������
o �ӱ��ؼ����undo��־��ȡ���ݡ�
o Ӧ�����е�redo��Ϣ��ֱ����������Ŀɻָ�����Ϊֹ��
���ڽڵ��������ҵ�redo��־��ĩβ��
�� ��5
��������״�������������SYSTAB_0��NDB$EVENTS�ڲ�ϵͳ����
���ڽڵ��������״νڵ�������
o �ڵ�����������������С�
o ���ڵ�ķ��������������ķ������бȽϣ�������ͬ����
o �����յ��ġ����Ա��ڵ����ڽڵ����������ڵ�ġ�INSERT��ʽ�����ݽ���ͬ����
o ���κ������£��ȴ����ٲó����ж��ı��ؼ����������ɡ�
�� ��6
�����ڲ�������
�� ��7
�����ڲ�������
�� ��8
��ϵͳ�����У��ؽ����е�������
�� ��9
�����ڲ�������
�� ��10
�ڽڵ��������״νڵ���������һ�Σ�API���ܻ����ӵ��ڵ㣬�������¼���
�� ��11
�ڽڵ��������״νڵ���������һ�Σ����¼����������ύ������صĽڵ㡣�¼���Ľڵ㸺������Ҫ���ݴ��ݸ�������
�����״�������ϵͳ������һ���ý�����ɣ����������������ܡ����ڽڵ��������״νڵ��������������̵������ζ�Žڵ������ܹ���Ϊ����Э������
�����ͻ����ṩ�������������������������嵥�У�node_idָ�������ݿ�ڵ�ID��ؼ���ALL��ָ�����Ӧ�õ����еĴ����ݽڵ��ϡ�
�� HELP
��ʾ�������п����������Ϣ��
�� SHOW
��ʾ���ڴ�״̬����Ϣ��
ע�ͣ���ʹ�ö�������ڵ�Ĵ��У����������ʾ�뵱ǰ����������ʵ�����������ݽڵ����Ϣ��
�� node_id START
������node_id��ʶ�����ݽڵ㣨���������ݽڵ㣩��
�� node_id STOP
ֹͣ��node_id��ʶ�����ݽڵ㣨���������ݽڵ㣩��
�� node_id RESTART [-N] [-I]
������node_id��ʶ�����ݽڵ㣨���������ݽڵ㣩��
�� node_id STATUS
��ʾ��node_id��ʶ�����ݽڵ㣨���������ݽڵ㣩��״̬��Ϣ��
�� ENTER SINGLE USER MODE node_id
���뵥�û�ģʽ���������ɽڵ�ID��node_id����ʶ��MySQL�������������ݿ⡣
�� EXIT SINGLE USER MODE
�˳����û�ģʽ���������е�SQL�ڵ㣨���������е�mysqld���̣��������ݿ⡣
�� QUIT
��ֹ�����ͻ��ˡ�
�� SHUTDOWN
�رճ�SQL�ڵ�֮������дؽڵ㣬���˳���
����һ���У������������¼���־���������Щ����ĵ���һ���У����������ڴ��������Լ��ӱ����лָ������
17.6.3. MySQL�������ɵ��¼�����
MySQL���ṩ�������¼���־��������cluster log��node logs��cluster log������־�����������дؽڵ����ɵ��¼���node logs���ڵ���־������¼ÿ�����ݽڵ�ı����¼���
�ɴ��¼���־�������ɵ���������ж��Ŀ�ĵأ������ļ�����������������̨���ڡ���syslog���ɽڵ��¼���־�������ɵ��������д�����ݽڵ�Ŀ���̨���ڡ�
���Զ��������¼���־�������ã�ʹ֮��¼��ͬ���¼��Ӽ���
ע�ͣ�����־��Ϊ�����ʹ�ó����Ƽ�����־��������Ϊ����1���ļ����ṩ�˹��������ص���־��Ϣ���ڵ���־��Ӧ��Ӧ�ó���Ŀ���������ʹ�ã������ڵ���Ӧ�ó�����롣
�ɸ������ֲ�ͬ���о�ʶ��ÿ��ֵ��ͨ�����¼���
�� Category����𣩣�����������ֵ֮һ��STARTUP, SHUTDOWN, STATISTICS, CHECKPOINT, NODERESTART, CONNECTION, ERROR,��INFO��
�� Priority�����ȼ������ɴ�1��15�����ֱ�ʾ����1����ʾ������Ҫ������15����ʾ�����Ҫ����
�� Severity Level�����ؼ��𣩣�����������ֵ֮һ��ALERT, CRITICAL, ERROR, WARNING, INFO, ��DEBUG��
�����Ǵ���־���ǽڵ���־�����ܸ�����Щ���Խ��й��ˡ�
17.6.3.1. �Ǽǹ�������
�����������������־�йأ�
�� CLUSTERLOG ON
����־��
�� CLUSTERLOG OFF
�رմ���־��
�� CLUSTERLOG INFO
���ڴ���־���õ���Ϣ��
�� node_id CLUSTERLOG category=threshold
��С�ڻ����threshold�����ȼ���category�¼���¼������־��
�� CLUSTERLOG FILTER severity_level
�����¼���־�л�Ϊָ����severity_level��
���±��У������˴���־�����ֵ��Ĭ�����ã������������ݽڵ㣩������¼������ȼ�ֵ���ڻ�������ȼ���ֵ���ͻ��ڴ���־�м�¼��
ע�⣬�¼��ǰ����ݽڵ�ͨ���ģ����ڲ�ͬ�Ľڵ������ò�ͬ����ֵ��
|
��� |
Ĭ����ֵ���������ݽڵ㣩 |
|
STARTUP |
7 |
|
SHUTDOWN |
7 |
|
STATISTICS |
7 |
|
CHECKPOINT |
7 |
|
NODERESTART |
7 |
|
CONNECTION |
7 |
|
ERROR |
15 |
|
INFO |
7 |
��ֵ���ڹ���ÿ������е��¼������磬�������ȼ�Ϊ3��STARTUP�¼������Ὣ���¼����־�У����ǽ�STARTUP����ֵ����Ϊ3���С�������ֵΪ3�����������ȼ����ڻ�С��3���¼���
����������¼������ؼ���ע�ͣ�������Unix��syslog�����Ӧ����LOG_EMERG��LOG_NOTICE���⣬δʹ�û�δӳ�����ǣ���
|
1 |
ALERT |
Ӧ���̸�����״��������ϵͳ���ݿ⡣ |
|
2 |
CRITICAL |
�ٽ�״�������豸�������Դ���㡣 |
|
3 |
ERROR |
Ӧ���Ը�����״���������ô���ȡ� |
|
4 |
WARNING |
���ܳ���Ϊ�����״����������Ҫ�ر����� |
|
5 |
INFO |
ͨ������Ϣ�� |
|
6 |
DEBUG |
������Ϣ������NDB�ؿ����� |
���Դ�ر��¼����ؼ�����������¼����ؼ�����ô���ȼ����ڻ���������ֵ���¼���������¼������ر����¼����ؼ�����ô������¼���ڸ����ؼ�����κ��¼���
�¼���־�м�¼���¼��������������ʽ��datetime [string] severity �C message�����磺
09:19:30 2005-07-24 [NDB] INFO -- Node 4 Start phase 4 completed
��������������ֵ��ͨ�����¼���������Լ�ÿһ����е����ؼ�������
CONNECTION�¼�
�����¼���ؽڵ�֮��������йء�
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
DB�ڵ������� |
8 |
INFO |
���ݽڵ������� |
|
DB�ڵ�Ͽ����� |
8 |
INFO |
���ݽڵ�Ͽ����� |
|
ͨ�Źر� |
8 |
INFO |
SQL�ڵ�����ݽڵ�������ѹر� |
|
ͨ�Ŵ� |
8 |
INFO |
SQL�ڵ�����ݽڵ�������Ѵ� |
CHECKPOINT�¼�
�����������־��Ϣ������йء�
��ע�ͣ�GCP =ȫ�ּ��㣬LCP =���ؼ��㣩��
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
��calc keep GCI�У�LCP��ֹͣ |
0 |
ALERT |
LCP��ֹͣ |
|
���ؼ���Ƭ����� |
11 |
INFO |
Ƭ���ϵ�LCP����� |
|
ȫ�ּ������ |
10 |
INFO |
GCP��� |
|
ȫ�ּ������� |
9 |
INFO |
����GCP����REDO��־д����� |
|
���ؼ������ |
8 |
INFO |
LCP��������� |
|
���ؼ������� |
7 |
INFO |
����LCP������������ |
|
����undo��־�ѷ�� |
7 |
INFO |
UNDO��־�ѷ�գ������Ҫ��� |
STARTUP�¼�
�����¼����ڳɹ���ʧ�ܵĽڵ������������ʱ���ɵġ����ǻ��ṩ�����������̽�չ״���йص���Ϣ����������־��йص���Ϣ��
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
�յ��ڲ������ź�STTORRY |
15 |
INFO |
������ɺ��յ�����Ϣ�� |
|
Undo��¼��ִ�� |
15 |
INFO |
|
|
�µ�REDO��־������ |
10 |
INFO |
GCI����X�����µĿɻָ�GCI Y |
|
����־������ |
10 |
INFO |
��־����X������MB Y��ֹͣMB Z |
|
�ܾ����ڵ�������� |
8 |
INFO |
�������ô���������ͨ�š����������⣬���ܽ��ڵ�����ڴ��С� |
|
DB�ڵ��ھ� |
8 |
INFO |
��ʾ���������ݽڵ㡣 |
|
DB�ڵ�������X��� |
4 |
INFO |
���ݽڵ�����������ɡ� |
|
�ڵ��ѱ��سɹ����� |
3 |
INFO |
��ʾ�ڵ㣬�����ڵ㣬�Լ���̬ID�� |
|
DB�ڵ��������ѿ�ʼ |
1 |
INFO |
NDB�ؽڵ����������� |
|
DB�ڵ����������������� |
1 |
INFO |
NDB�ؽڵ��������� |
|
DB�ڵ�رղ��������� |
1 |
INFO |
���ݽڵ�Ĺرղ����ѿ�ʼ |
|
DB�ڵ�رղ���ʧ�� |
1 |
INFO |
�������ر����ݽڵ㡣 |
NODERESTART�¼�
�����¼����������ڵ�ʱ�����ģ�����ڵ��������̵ijɹ���ʧ����ء�
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
�ڵ�ʧ�ܽ���� |
8 |
ALERT |
ͨ���ڵ�ʧ�ܽε���� |
|
�ڵ�ʧ�ܣ��ڵ�״̬ΪX |
8 |
ALERT |
ͨ���ڵ���ʧ�� |
|
ͨ���ٲó����� |
2 |
ALERT |
�����ٲó��ԣ���8�ֲ�ͬ�Ŀ��ܽ���� �� �ٲü��ʧ�ܣ�ʣ��ڵ�����1/2�� �� �ٲü��ɹ����ڵ������ �� �ٲü��ʧ�ܣ���ʧ�ڵ��� �� ���������Ҫ���ٲ� �� �ٲóɹ������Խڵ�X�������Ӧ �� �ٲ�ʧ�ܣ����Խڵ�X�ĸ����Ӧ �� ������������õ��ٲó��� �� ���������δ�����ٲó��� |
|
�����Ƭ�θ��� |
10 |
INFO |
|
|
�����Ŀ¼��Ϣ���� |
8 |
INFO |
|
|
����˷�����Ϣ���� |
8 |
INFO |
|
|
��ʼ����Ƭ�� |
8 |
INFO |
|
|
���������Ƭ�εĸ��� |
8 |
INFO |
|
|
GCP���������� |
7 |
INFO |
|
|
GCP��������� |
7 |
INFO |
|
|
LCP���������� |
7 |
INFO |
|
|
LCP��������ɣ�״̬= X�� |
7 |
INFO |
|
|
ͨ���Ƿ������ٲó��� |
6 |
INFO |
�����ٲó���ʱ����7�ֿ��ܵĽ���� �� ���������������ٲ��߳�[state=X] �� ���ٲó���ڵ�X [ticket=Y] �� �����ٲó���ڵ�X [ticket=Y] �� �����ٲó���ڵ�X [ticket=Y] �� ��ʧ���ٲó���ڵ�X �C ����ʧ�� [state=Y] �� ��ʧ���ٲó���ڵ�X �C �����˳� [state=Y] �� ��ʧ���ٲó���ڵ�X <error msg> [state=Y] |
STATISTICS�¼�
�����¼�����ͳ�����ԡ������ṩ����Ӧ����Ϣ���������������������Ŀ����Ũ�Ƚڵ㷢�ͻ���յ����������Լ��ڴ�ʹ���ʵȡ�
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
ͨ����ҵ�ճ�ͳ�� |
9 |
INFO |
ƽ�����ڲ���ҵ�ճ�ͳ�� |
|
���͵��ֽ��� |
9 |
INFO |
�������ڵ�X��ƽ���ֽ��� |
|
���յ��Լ�# |
9 |
INFO |
�ӽڵ�X���յ�ƽ���ֽ��� |
|
ͨ������ͳ�� |
8 |
INFO |
������Ŀ���ύ��������ȡ��������ȡ������д�����������������Ŀ��������Ϣ���Լ��������� |
|
ͨ������ |
8 |
INFO |
������Ŀ |
|
ͨ�������� |
7 |
INFO |
|
|
�ڴ�ʹ�� |
5 |
INFO |
�����ڴ�������ڴ��ʹ���ʣ�80%��90%��100%�� |
ERROR�¼�
��Щ�¼���ش���澯�йأ��������1�����������¼��������������ش���ϻ�ʧ�ܡ�
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
��ʧȥ���������� |
8 |
ALERT |
��ʧȥ�����������ڵ�X������ |
|
���������� |
2 |
ERROR |
|
|
�������澯 |
8 |
WARNING |
|
|
ʧȥ���� |
8 |
WARNING |
�ڵ�Xʧȥ����#Y |
|
һ���Ը澯�¼� |
2 |
WARNING |
|
INFO�¼�
��Щ�¼������˹��ڴ�״̬�ʹ�ά�����һ����Ϣ������־����������ȡ�
|
�¼� |
���ȼ� |
���ؼ��� |
���� |
|
�������� |
12 |
INFO |
�������������ڵ�X |
|
������־�ֽ� |
11 |
INFO |
��־���֣���־�ļ���MB |
|
һ����Ϣ�¼� |
2 |
INFO |
|
���õ��û�ģʽ�����ݿ����Ա�ܹ��������ݿ�ϵͳ�ķ���������1��MySQL��������SQL�ڵ㣩�����뵥�û�ģʽʱ������������MySQL���������������Ӿ���ǡ���رգ����������������е���������������������������κ�������
һ���ؽ��뵥�û�ģʽ��ֻ��ָ����SQL�ڵ����Ȩ�������ݿ⡣ʹ��ALL STATUS����ɲ鿴�ؽ��뵥�û�ģʽ��ʱ�䡣
ʾ����
NDB> ENTER SINGLE USER MODE 5
ִ�и�������Ҵؽ��뵥�û�ģʽ�ڵ�IDΪ5��SQL�ڵ㽫��Ϊ����Ψһ�������û���
����������ָ���Ľڵ������MySQL�������ڵ㣬���ָ���κ��������͵Ľڵ㣬�����ܾ���
ע�ͣ�ִ����������ʱ��ָ���ڵ��������������е�������������������ӹرգ����ұ���������������
ʹ��EXIT SINGLE USER MODE����ܹ��������ݽڵ��״̬�ӵ��û�ģʽ����Ϊ����ģʽ�����ڵȴ����ӵ�MySQL���������������ڼ��������������õĴأ������������������ӡ���״̬�仯�ڼ�ͱ仯֮��ָ��Ϊ���û�SQL�ڵ��MySQL���������������У���������ӵĻ�����
ʾ����
NDB> EXIT SINGLE USER MODE
�����ڵ��û�ģʽ��ʱ������ڵ�ʧ�ܣ��Ƽ��Ĵ��������ǣ�
1. �������еĵ��û�ģʽ����
2. ����EXIT SINGLE USER MODE���
3. �����ص����ݽڵ㡣
��
�� ���뵥�û�ģʽ֮ǰ�������ݿ⡣
�� Metadata��Ԫ���ݣ����������ݿ�������ƺͶ��塣
�� Table records������¼����ִ�б���ʱʵ�ʱ��������ݿ���е����ݡ�
�� Transaction log��������־����ָ������Լ���ʱ�����ݱ��������ݿ��е�������¼��
ÿһ���־��ᱣ���ڲ��뱸�ݵ����нڵ��ϡ��ڱ��ݹ����� ��ÿ���ڵ���Ὣ���������ֱ����ڴ����ϵ������ļ��У�
�� BACKUP-backup_id.node_id.ctl
����������Ϣ��Ԫ���ݵĿ����ļ���ÿ���ڵ���Ὣ��ͬ�ı����壨���ڴ��е����б����������Լ��ĸ��ļ��С�
�� BACKUP-backup_id-0.node_id.data
��������¼�������ļ������ǰ�Ƭ�α���ģ�Ҳ����˵���ڱ��ݹ����У���ͬ�Ľڵ�ᱣ�治ͬ��Ƭ�Ρ�ÿ���ڵ㱣����ļ���ָ���˼�¼�������ı��ʼ���ڼ�¼�嵥������һ�������������м�¼У��͵Ľ�ע��
�� BACKUP-backup_id.node_id.log
�������ύ����ļ�¼����־�ļ�������־�У����������ڱ����б���ı��ϵ������뱸�ݵĽڵ㽫���治ͬ�ļ�¼��������Ϊ����ͬ�Ľڵ������˲�ͬ�����ݿ�Ƭ�Ρ�
���������е������У�backup_idָ���DZ���ID��node_id�Ǵ����ļ��Ľڵ��ΨһID��
17.6.5.2. ʹ�ù�����������������
��ʼ����ǰ����ȷ����Ϊ���ݲ���ǡ���������˴ء�����μ�17.6.5.4�ڣ����ر��ݵ����á�����
ʹ�ù����������������ݰ������²��裺
1. ��������������(ndb_mgm)��
2. ִ������START BACKUP��
3. ����������������Ϣ��ָʾ���ݿ�ʼ������Ӧ������ζ�Ź����������������ύ���˴أ�����δ�յ��κλ�Ӧ��
4. �����������ظ�������backup_id��ʼ�������У�backup_id�Ǹñ��ݵ�ΨһID�����δ���������ã���ID���������ڴ���־�У�������ζ�Ŵ����յ�����ʼ������������������ʾ��������ɡ�
5. ����������������Ϣ������backup_id�������֪ͨ���ݲ����ѽ�����
Ҫ��������ڴ����ı��ݣ�
1. ����������������
2. ִ������ABORT BACKUP backup_id��backup_id�ǵ����ݿ�ʼʱ�����ڹ���������Ӧ���еı���ID������Ϣ������backup_id�������У���
3. ��������������Ϣ������ָʾ�ı���backup_id��ȷ�Ϸ�������ע�⣬��δ�յ��Ը������ʵ�ʻ�Ӧ��
4. һ�������˱��ݣ�������������ͨ��������backup_id��XYZ��������������ζ�Ŵ���ֹ�˱��ݣ����Ӵ��ļ�ϵͳ��ɾ������ñ����йص������ļ���
��ϵͳshell��ʹ���������Ҳ�ܷ�������ִ�еı��ݣ�
shell> ndb_mgm -e "ABORT BACKUP backup_id"
ע�ͣ�ִ�з�������ʱ�����û��IDΪbackup_id�ı��ݣ�������������������κ���ȷ��Ӧ�����ǣ�����������Ч��������ڴ���־�и�����
�ػָ���������Ϊ������������ʵ�ù���ndb_restoreʵ�ֵģ�������ȡ�ɱ��ݴ������ļ��������������Ϣ�������ݿ⡣����Ϊÿ�鱸���ļ�ִ�лָ�����Ҳ����˵��ִ�д����봴������ʱ���е����ݿ�ڵ�����ͬ��
�״�ִ�лָ�����ʱ������Ҫ�ָ�Ԫ���ݡ����仰�����������´������ݿ����ע�⣬��ʼִ�лָ�����ʱ������Ӧ��һ�������ݿ⣩���ָ�������ڴ���˵�൱��API����ˣ���Ҫһ���������ӣ��Ա������������ʹ��ndb_mgm����SHOW����ϵͳshell��ʹ��ndb_mgm
-e SHOW������ɸò�����������֤������ʹ�ÿ��ء�-c
connectstring����ȷ��MGM�ڵ��λ�á������������ַ����ĸ�����Ϣ����μ�17.4.4.2�ڣ���MySQL�������ַ������������ļ�����λ�ڻָ��������������Ŀ¼�¡�
�ܹ�ʹ���봴�����������ò�ͬ�����ý����ݻָ������ݿ⡣���磬���ڱ���IDΪ12�ı��ݣ��ñ������ھ����������ݿ�ڵ㣨�ڵ�ID��2��3���Ĵ��д����ģ����Խ���ָ�������4���ڵ�Ĵ��С�������ndb_restore�����������Σ�Ϊ��������ʱ��ÿ�����ݿ�ڵ�����һ�Ρ�
ע�ͣ����ڿ��ٻָ����ܹ��Բ��з�ʽ�ָ����ݣ����������㹻�Ŀ��ô����ӡ�Ȼ���������ļ�����ʼ��ǰ����־�ļ���
��4�����ڱ��ݵĻ������ò�����
�� BackupDataBufferSize
������д�����֮ǰ���ڶ����ݽ��л��崦�����ڴ�����
�� BackupLogBufferSize
����־��¼д�����֮ǰ���ڶ�����л��崦�����ڴ�����
�� BackupMemory
�����ݿ�ڵ���Ϊ���ݷ�������ڴ档��Ӧ�Ƿ�����������ݻ�����ڴ�ͷ����������־������ڴ�֮�͡�
�� BackupWriteSize
д����̵Ŀ��С���������ڱ������ݻ���ͱ�����־����
������Щ�����ĸ���ϸ�ڣ���μ�17.4�ڣ���MySQL�ص����á���
NDB��֧���ظ��Ķ�ȡ���������ڻָ����̣���������ᵼ�����⡣���ܱ��ݽ��̡�hot�������ӱ��ݻָ�MySQL�ز�����100����hot���Ľ��̡���ԭ�����ڣ��ڻָ�����ִ���ڼ䣬�������е��������ѻָ��������л�ȡ�����ظ��Ķ�������ζ�ţ����ָ����ڽ���ʱ�����ݵ�״̬�Dz�һ�µġ�
17.7. ʹ����MySQL�صĸ��ٻ���
��ʹ��1996�꿪ʼNDB�ص����֮ǰ���ڴ����������ݿ�Ĺ�����������һ����Ҫ������Ȼ�������нڵ�֮���ͨ�����⡣����Ϊ��ˣ��ӿ�ʼ���ʱ��NDB�ؾ�����ʹ�ö��ֲ�ͬ�����ݴ�����ơ��ڱ��ֲ��У�����ʹ����������������
Ŀǰ��MySQL�ش������������ֲ�ͬ��������֧�֡�Ŀǰ�Ĵ�����û����õ�����̫���ϵ�TCP/IP��������Ϊ�������ڡ���Ҳ������Ϊֹ��MySQL���о�����Ѳ��ԵĴ�������
��������Ŭ������ȷ����ndbd���̵�ͨ���Ǿ����ܴ�ġ���顱��������Ϊ�������������е����ݴ������͡�
������Ҫ�����û���Ҳ��ʹ�ôػ����Խ�һ����ǿ���ܡ�ʵ�����ķ�ʽ�����֣���ʹ���ܴ���������Ķ��ƴ���������ʹ�����ƹ�TCP/IP��ջ������ʵʩ����������ʹ����Dolphin������SCI����ģ����չ�ļ�������ӽӿڣ��������������༼�����������顣
�ڱ����У����ǽ�������θı�Ϊ����TCP/IPͨ�����õĴأ���ʹ��SCI���֡����ĵ�����2004��10��1�շ�����SCI����2.3.0�档
ǰ������
�����κδ���ʹ��SCI���ֵĻ������������䱸SCI����
�ܹ����κΰ汾��MySQL��һ��ʹ��SCI���֡�����Ҫ���ⴴ����������Ϊ��������MySQL�������ṩ���������ֵ��á����ǣ�Ŀǰ����Linux 2.4��2.6�ں��ϲ�֧��SCI���֡����ܵ�ĿǰΪֹ���ǽ���Linux 2.4�Ϻ�ʵ����㣬��һЩ��������ϵͳ��Ҳ�ɹ�������SCI��������
����SCI���֣������ֻ���Ҫ��
1. ����SCI���ֿ⡣
2. ��װSCI�����ں˿⡣
3. ��װ1����2�������ļ���
4. ����Ϊ��������������MySQL�ؽ��̵�shell����SCI���ֿ⡣
���ڴ��㽫SCI�������ڽڵ���ͨ�ŵĴأ���ҪΪ���е�ÿ̨�����ظ��ý��̡�
Ҫ��ʹSCI���ֹ�������Ҫ���������������
1. ��������SCI���ֿ��DIS֧�ֿ��Դ����������
2. ����SCI���ֿⱾ����Դ����������
Ŀǰ������Դ���ʽ�ṩ�����ǡ���д���ĵ�ʱ���õ����°汾���������ֱ���DIS_GPL_2_5_0_SEP_10_2004.tar.gz��SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz��������վ�㣬���ҵ����ǣ�Ҳ�����ҵ����µİ汾����http://www.dolphinics.no/support/downloads.html��
��������װ
��ÿ�������������Ӧ�����ǽ����ǡ����Ŀ¼�£���SCI���ֿ�����DIS�����µ�Ŀ¼�С�Ȼ����Ҫ�����⡣�������ʾ���У���������Linux/x86ƽ̨��ִ�и�������������
shell> tar xzf DIS_GPL_2_5_0_SEP_10_2004.tar.gz
shell> cd DIS_GPL_2_5_0_SEP_10_2004/src/
shell> tar xzf ../../SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz
shell> cd ../adm/bin/Linux_pkgs
shell> ./make_PSB_66_release
�ܹ�Ϊ64λ������������Щ�⡣Ҫ��Ϊʹ��64λ��չ��Opteron CPU������Щ�⣬������make_PSB_66_X86_64_release������make_PSB_66_release�����������������Itanium�����Ͻ��еģ�Ӧʹ��make_PSB_66_IA64_release��X86-64����Ӧ����Intel EM64T��ϵ�ṹһ�������������δ���ԣ���������֪����
��ɴ������̺���zipped tar�ļ��пɷ����ѱ���õĿ⣬�ļ������Ʒ���DIS-<operating-system>-time-date�����ڣ��ɽ���������װ��ǡ��λ�á��ڱ����У�����ʹ�õİ�װĿ¼��/opt/DIS��ע�ͣ���ܿ�����Ҫ��ϵͳ���û��������������������
shell> cp DIS_Linux_2.4.20-8_181004.tar.gz /opt/
shell> cd /opt
shell> tar xzf DIS_Linux_2.4.20-8_181004.tar.gz
shell> mv DIS_Linux_2.4.20-8_181004 DIS
��������
���ˣ����еĿ�Ͷ������ļ����Ѱ�װ����ǡ����λ�ã�����ȷ��SCI����SCI�ĵ�ַ�ռ䷶Χ��ӵ��ǡ���Ľڵ�ID��
���к���IJ���ǰ������ȷ������ṹ�����ڸ����Σ������ֿ�ʹ�õ�����ṹ��
�� һά�������硣
�� 1������SCI��������ÿ���������˿���1����������
�� 2��3��������
ÿ�����˽ṹ�����Լ��ġ������ṩ�ڵ�ID�ķ�������������˼�Ҫ���ۡ�
���������õĽڵ�ID��4�ķ�0������4��8��12����
��һ�����е�ѡ����SCI��������1��SCI��������8���˿ڣ�ÿ���˿ڶ���֧��1�����������б�Ҫȷ����ͬ�Ļ�����ʹ���˲�ͬ�Ľڵ�ID�ռ䡣���ڵ��͵����ã���1���˿�ʹ�õĽڵ�ID����64��4��60������������64���ڵ�ID��68��124��ָ������һ���˿ڣ��������ƣ��ڵ�ID 452��508����ָ������8���˿ڡ�
����2ά��3ά�������ṹ��ÿ���ڵ�λ�ڸ�ά�У��ڵ�1ά�У����ڵ������Ϊ4���ڵ�2ά�У�����Ϊ64���ڵ�3ά�У�������õĻ���������Ϊ1024�����ڸ��꾡���ĵ�����μ�Dolphin����վ��
�����ǵIJ����У������˽�������ʽ������������ʹذ�װӦ��ʹ�õ���2ά��3ά�������ṹ�����ý�������ʽ���е��ŵ��ǣ�ʹ��˫SCI����˫���������ܹ�������ش����������磬SCI�����ϵ�ƽ�������л�ʱ����100��������������SCI����ʵʩ��MySQl���е�SCI������֧�ָýṹ��������Ҳ���ڷ�չ���С�
����2D/3D�������������л�Ҳ�ǿ��ܵģ�����Ҫ�����нڵ㷢�ͷ����µ�·��������Ȼ���������Ҫ100�������Ҿ�����ɣ����ڴ�����߿��������Σ����ǿɽ��ܵġ�
ͨ���������ݽڵ�ǡ�������ڽ���ʽ��ϵ�ṹ�У��ܹ�ʹ��2���������������ṹ����16̨�����������һ���κε�����Ͼ��������1̨���ϵļ����������32̨�������2̨��������Ҳ���������ķ�ʽ���ôأ��κε�����Ͼ����ᵼ��2�����ϵĽڵ㶪ʧ���ڴ�����£�Ҳ��֪����һ�Խڵ��յ�Ӱ�졣��ˣ�ͨ���������ڵ����ڲ�ͬ�Ľڵ��飬���ܴ�������ȫ�ġ�MySQL�ء�
Ҫ��ΪSCI�����ýڵ�ID����ʹ��/opt/DIS/sbinĿ¼�е���������ڱ����У���-c 1��ָ����SCI���ı��������ڻ�����ֻ��1�鿨������Ϊ1������-a 0��ָ����������0����68���ǽڵ�ID��
shell> ./sciconfig -c 1 -a 0 -n 68
�����ͬһ̨�������ж��SCI����ʹ����������ٶ���ǰ�Ĺ���Ŀ¼��/opt/DIS/sbin������ȷ���Ŀ鿨ʹ���ĸ���ۣ�
shell> ./sciconfig -c 1 -gsn
��������SCI�������кš�Ȼ���á�-c 2���ظ��ò��裬�������ƣ��Ի����ϵ�ÿ�鿨����һ����ÿ�鿨��1�����ƥ���Ϊ���п����ýڵ�ID��
��װ�˱�Ҫ�Ŀ�Ͷ������ļ�����������SCI�ڵ�ID����һ�������ô�����������IP��ַ����SCI�ڵ�ID��ӳ�䡣���������SCI���������ļ�����ɣ����ļ�Ӧ������Ϊ/etc/sci/scisock.conf���ڸ��ļ��У�ͨ��ǡ����SCI����SCI�ڵ�ӳ�䵽��֮ͨ�ŵ���������IP��ַ�����������һ���ܼ������ļ�ʾ����
#host #nodeId
alpha 8
beta 12
192.168.10.20 16
Ҳ�ܶ����ý������ƣ�ʹ���Ӧ������Щ�����Ŀ��ö˿��Ӽ��ϡ�Ҳ��ʹ�ö���������ļ�/etc/sci/scisock_opt.conf��ɸ����ã�������ʾ��
#-key -type -values
EnablePortsByDefault yes
EnablePort tcp 2200
DisablePort tcp 2201
EnablePortRange tcp 2202 2219
DisablePortRange tcp 2220 2231
��������װ
�������������ļ��ɰ�װ��������
����Ӧ��װ�ײ�������Ȼ��װSCI����������
shell> cd DIS/sbin/
shell> ./drv-install add PSB66
shell> ./scisocket-install add
���Ը�⣬�ɵ��ýű�����ʵSCI���������ļ��е����нڵ��Ƿ���ܷ��ʣ�ͨ���÷�ʽ��鰲װ��
shell> cd /opt/DIS/sbin/
shell> ./status.sh
������ִ�����Ҫ����SCI�������ã���Ҫʹ��ksocketconfig����ɸ�����
shell> cd /opt/DIS/util
shell> ./ksocketconfig -f
��������
Ϊ��ȷ��SCI������ʵ��ʹ�ã���ʹ��latency_bench���Գ���ʹ�ø�ʵ�ù��ߵķ�����������ͻ����ܹ����ӷ������Բ������ӵĵȴ�ʱ�䣬ͨ���۲�ȴ�ʱ�䣬�ɷ�����ж��Ƿ�������SCI����ע�ͣ�ʹ��latency_bench֮ǰ����Ҫ���û�������LD_PRELOAD����μ����ں���Ľ��ܣ���
Ҫ�����÷���������ʹ���������
shell> cd /opt/DIS/bin/socket
shell> ./latency_bench -server
Ҫ�����пͻ��ˣ��ٴ�ʹ��latency_bench������ʱ���á�-client��ѡ�
shell> cd /opt/DIS/bin/socket
shell> ./latency_bench -client server_hostname
��ĿǰΪֹ��Ӧ�����SCI�������ã�����MySQL����������ʹ��SCI���ֺ�SCI��������������μ�17.4.4.10�ڣ���MySQL��SCI�������ӡ�����
������
�ý��̽������IJ���������MySQL�ء�Ҫ������SCI���֣�������ndbd��mysqld��ndb_mgmd֮ǰ����Ҫ���û�������LD_PRELOAD���ñ���Ӧָ������SCI���ֵ��ں˿⡣
Ҫ����bash shell������ndbd����ִ���������
bash-shell> export LD_PRELOAD=/opt/DIS/lib/libkscisock.so
bash-shell> ndbd
��tcsh�����£���ʹ���������������ͬ������
tcsh-shell> setenv LD_PRELOAD=/opt/DIS/lib/libkscisock.so
tcsh-shell> ndbd
ע�ͣ�MySQL�ؿ��Խ�ʹ��SCI���ֵ��ں˱��塣
�����ַ��ʷ�����
�� ��������
ͨ���������ط��ʼ�¼�����������£�һ�ν�����һ����¼������ζ�Ÿõ�һ�����踺�������ڶ�TCP/IP��Ϣ��ȫ�������Լ��ڶ�ij����л�������������һ���з��������������������������Щ�������ֵ����ñ�ҪTCP/IP��Ϣ�ͳ����л��Ŀ��������TCP/IP��Ϣ������ͬĿ��ģ��������ö����TCP/IP��Ϣ��
�� Ψһ������
Ψһ�������������������ƣ�������ڣ�Ψһ����������Ϊ���������ϵĶ�ȡ����ִ�еģ�Ȼ���������ڱ��ϵ��������ʡ����ǣ�MySQL������������һ�������Ҷ��������Ķ�ȡ����ndbd�������ġ���������Ҳ����������������
�� ȫ��ɨ��
���ڱ���ѯ��������������ʱ����ִ��ȫ��ɨ�衣�⽫��Ϊ��һ��������ndbd���̣��ý������ɨ���Ϊ�����д�ndbd�����Ͻ��е�һ�鲢��ɨ�衣��δ����MySQL�ذ汾�У�SQL�ڵ��ܹ�����ijЩɨ�衣
�� ʹ�����������ķ�Χɨ��
ʹ����������ʱ������ʹ����ȫ��ɨ����ͬ�ķ�ʽִ��ɨ�裬��֮ͬ�����ڣ�����ɨ��λ��MySQL��������SQL�ڵ㣩�������ѯʹ�õķ�Χ�ڵļ�¼�������а��������������� ���е���������ʱ�����Բ��з�ʽɨ�����з�����
Ϊ�˼����Щ���ʷ����Ļ������ܣ����ǿ�����һ�������Ϊ�����֮һ��testReadPerf�ܹ����Լĺ�������ʽ������Ψһ�����ʡ�ͨ���������ص�һ��¼��ɨ�����û����ܲ�����Χɨ������ÿ��������⣬����1���û��ı��壬�������˷�Χɨ������ȡ������¼��
���������Ǿ���ȷ���������ʵĿ������Լ�����¼ɨ����ʵĿ��������ܸ��ݻ������ʷ�������ͨ��ý���Ӱ�졣
�����ǽ��еIJ����У�Ϊ����TCP/IP���ֵ�������������ʹ��SCI���ֵ��������ý����˻������á���������������ǹ����������ʵģ�ÿ�η���20����¼��ʹ��2KB�ļ�¼ʱ�����з��ʺ���ʽ����֮��IJ��콫����3��4��������2KB�ļ�¼��δ����SCI���֡����������������Ͻ��еģ��ô����������ݽڵ㣬���������ݽڵ�������2̨˫CPU�����ϣ�������ΪAMD MP1900+��
Access type: TCP/IP sockets SCI Socket
Serial pk access: 400 microseconds 160 microseconds
Batched pk access: 28 microseconds 22 microseconds
Serial uk access: 500 microseconds 250 microseconds
Batched uk access: 70 microseconds 36 microseconds
Indexed eq-bound: 1250 microseconds 750 microseconds
Index range: 24 microseconds 12 microseconds
���ǻ�ִ������һ����ԣ��Լ��SCI���ֵ������Լ�SCI�����������ܣ�������������TCP/IP�����������ܽ����˱Ƚϡ����в��Ծ��������������ʷ���������ô��ж��̷߳�ʽ������ö��߳�����ʽ��
���Խ��������SCI���ֱ�TCP/IPԼ��100������SCI������ȣ��ڴ��������£�SCI���������ٶȸ��졣�ھ��кܶ��̵߳IJ��Գ����г�����1��ֵ�ù�ע�����������������mysqld����һ��ʹ��ʱ��SCI��������ִ�����ܲ����ܺá�
���ǵó�����������ǣ����ڴ����������TCP/IP��ȣ����˺�����ͨ�����ܲ�����Ϊ��ע���˵�����⣬ʹ��SCI�����ܽ���������Լ100������ɨ�������ռ�ô��������ʱ�䣬��ִ�д������������ʣ��ͻ���ָ����������������£�ndbd�����е�CPU����������ռ�ÿ������൱�֡�
����ʹ��SCI��������ȡ��SCI���֣�������ndbd����֮���ͨ�������塣���CPU��ר������ndbd���̣�ʹ��SCI������ҲҲ�������壬������ΪSCI��������ȷ���ý���������Ϣ����һ����Ҫ�����ǣ�����ȷ����ndbd���̵����ȼ������ض������ã���ʹ�����˺ܳ���ʱ�䣬�����ȼ�Ҳ����ɥʧ��������Linux 2.6��ͨ��������������CPU����ʵ�ֵ�������������������ǿ��ܵģ���ʹ��SCI������ȣ�ndbd���̽����10��70��������������ִ�и����Լ����ܵIJ���ɨ�����ʱ�����������ϴ���
���ڼ�����أ����������������Ż�����ʵʩ����������Myrinet����������̫����Infiniband������������VIA�ӿڡ�����Ϊֹ�����ǽ���SCI����һ�������MySQL�ء����ǻ��ṩ�������ĵ������У����������ʹ�����MySQL�صij���TCP/IP������SCI���ֵķ�����
17.8. MySQL�ص���֪����
�ڱ����У������г���5.1.xϵ���ж�MySQL�ص�һЩ��֪���ƣ�����ʹ��MyISAM��InnoDB�洢����ʱ���õ����Խ����˱Ƚϡ�Ŀǰ���в������ڼ����Ƴ���MySQL 5.1�汾�д�����Щ���⣬���ǣ����ǽ��ں����İ汾ϵ���У��ṩ�ⷽ��IJ��������������������MySQLȱ�����ݿ⣨http://bugs.mysql.com���еġ��ء���𣬿ɷ������Ǵ����ڼ����Ƴ���MyAQL 5.1���и�������֪ȱ�ݣ�������Ϊ��5.1���Ļ�����
��ע�ͣ��ڱ���ĩβ���г����ڵ�ǰ�汾���ѽ����MySQL 5.0���е�һЩ���ˣ���
�� ��еIJ����������������е�Ӧ�ó���ʱ���´���
o ��֧���ı�������
o ��֧��Geometry�������ͣ�WKT��WKB����
�� ���ƻ���Ϊ�еIJ����������������е�Ӧ�ó���ʱ���ܵ��´���
o û������IJ��ֻع����ܡ��ظ��������ƴ���ᵼ����������Ļع���
o ���ںܶ�����õ�Ӳ���ƣ�����ʹ�ô��еĿ������ڴ��������ơ��������ò����������嵥����μ�17.4.4�ڣ��������ļ�������������ò�����������������ЩӲ���ư�����
�� ���ݿ��ڴ��С�������ڴ��С���ֱ���DataMemory��IndexMemory����
�� �����ܹ�ִ�е��������������ʹ�����ò���MaxNoOfConcurrentOperations�������á�ע���������أ�TRUNCATE TABLE��ALTER TABLE��ͨ�����ж��������Ϊ����������д����ģ�������ܸ����Ƶ�Լ����
�� ����������йصIJ�ͬ���ơ����磬ÿ���������������������MaxNoOfOrderedIndexesȷ���ġ�
o ��NDB���У����ݿ����ơ������ƺ��������Ʋ��������������������е�һ�������������ƽ����ض���31���ַ����ض̺��������Ψһ�ģ������´������ݿ����ƺͱ����������Ϊ122���ַ���Ҳ����˵��NDB�ر��������Ϊ122���ַ���ȥ�ñ����������ݿ�������е��ַ�������
o ���еĴر��о��й̶����ȡ�����ζ�ţ����磩����������н�������Խ�Сֵ��1������VARCHAR�ֶΣ���ʹ��MyISAM�������ͬ����������ȣ�ʹ��NDB�洢����ʱ��Ҫ������ڴ�ʹ��̿ռ䡣���仰��������VARCHAR�У�������Ĵ洢�ռ��������ͬ��С��CHAR���������ͬ��
o �����ݿ��е�������Ŀ����Ϊ1792��
o ÿ�����������������Ϊ128��
o ��һ�е����������СΪ8K��������������BLOB���е����ݡ�
o ÿ�������������Ϊ32��
�� ��֧�ֵ����������ᵼ�´�������֧�ֻ�ǿ�ƣ���
o ����ṹ�������ԣ�������MyISAM����������
o ������Լ��Ա����Ļع��������ԣ�������MyISAM��������
�� �����Լ��������йص�����
o ���ڶ�NDB�洢������������ʣ����ڲ�ѯ�������⣬��MyISAM��InnoDB��������ȣ�ִ�кܶΧɨ��ʱ�����������
o ��֧�ַ�Χͳ���еļ�¼����ijЩ����£������ɷ����Ų�ѯ�ƻ����ɲ���USE INDEX��FORCE INDEX��ܸ����⡣
o ����ʹ��USING HASH������Ψһ�Թ�ϣ���������NULL�Ǽ���һ���֣�����ʹ�������������ʱ���
o MySQL�ز�֧�ִ����ϵij����ύ���ύ�������ƣ�������֤���ύʱ�Ὣ��־д����̡�
�� ��ʧ���ԣ�
o Ψһ֧�ֵĸ��뼶����READ_COMMITTED��InnoDB֧��READ_COMMITTED��READ_COMMITTED��REPEATABLE_READ��SERIALIZABLE�������������Ӱ������ݿⱸ�ݺͻָ��ĸ�����Ϣ����μ�17.6.5.5�ڣ������ݹ���������ų�����
o ��֧�ִ����ϵij����ύ���ύ�������ƣ�������֤���ύʱ�Ὣ��־д����̡�
�� ���MySQL�������йص���������MyISAM��InnoDB�أ���
o ���ж��MySQL������ʱ��ALTER TABLEδ��ȫ�������ֲ�ʽ����������
o ����ڶ��MySQL�������Ͻ����˸��£�MySQL���ƹ��ܲ�����ȷ���������ǣ�������ݿ������������Ӧ�ü�������ɵģ���������Щ�����ϷǷ���������ô��ʹ���ƹ�����ȷ������
o ���ڷ�����ͬMySQL�صĶ�MySQL����������֧�����ݿ���Զ����֣�autodiscovery�����ܡ����ǣ�������£�֧�ֶԱ����Զ����֣�autodiscovery�����ܡ�����ζ�ţ���������Ϊdb_name�����ݿ��ʹ��1��MySQL�����������˸����ݿ��Ӧ�ڷ�����ͬMySQL�ص�ÿ������MySQL�������Ϸ���CREATE DATABASE db_name��䣨��MySQL 5.0.2��ʼ���㻹��ʹ��CREATE SCHEMA db_name;����һ���Ը���MySQL����������˸ò�����������Ӧ�ܼ����ݿ����������������
�� ����MySQL���йص���������MyISAM��InnoDB�أ���
o ����ʹ�õ����л������������ͬ����ϵ�ṹ��Ҳ����˵�����г��ؽڵ�Ļ���������big-endian��little-endian�����ܻ��ʹ�������ߡ����磬������������PPC�ϵĹ����ڵ�ָ��������x86�����ϵ����ݽڵ㡣�����Ʋ������ڼ�����mysql�������ͻ��ˣ����ܻ���ʴص�SQL�ڵ㣩�Ļ�����
o ������ʹ��ALTER TABLE��CREATE INDEX��ɵ�����ִ�����߷������ģ�������ΪNDB�ز�֧�����������Զ���⣨���ǣ��ܹ������ʹ�ò�ͬ�洢����ı���Ȼ��ʹ�á�ALTER TABLE tbl_name ENGINE=NDBCLUSTER;������ת��ΪNDB������������£���Ҫ����FLUSH TABLES���ǿ�ƴط��ֱ仯����
o �����������ӻ������ڵ㣨��ʱ���������أ���
o ʹ�ö������������ʱ��
�� �����������ַ�������ȷΪ�ڵ�ָ��ID��������Ϊ���ڶ�������������ϣ��Զ�����Ľڵ�ID��������������
�� ����ʮ��С�ģ�ȷ�����еĹ���������������ͬ�����á��ضԴ˷��治�����κ������飬
�� Ҫ��ʹ�����ڵ��ܷ��ֱ˴˵Ĵ��ڣ������˴غ�����������е����ݽڵ㣨��ϸ������μ�Bug #13070����
o ��֧���������ݽڵ�Ķ������ӿڡ����ʹ��������ӿڣ������������⣬ԭ�����ڣ��ڳ���ijһ���ݽڵ�ʧ�ܵ�����£�SQL�ڵ㽫�ȴ���ȷ�ϸ����ݽڵ��Ƿ�������⣬�����ڸ����ݽڵ����һ·���Ա��ִ�״̬��SQL�ڵ���Զ�����յ���ȷ����Ϣ����ᵼ�´���������
o ���ݽڵ�������ĿΪ48��
o MySQL�����ܵ����ڵ���Ϊ63���ڸ���ֵ�а������е�MySQL��������SQL�ڵ㣩�����ݽڵ������������
���ǵ����ڿ�ʼʱ�趨��������������ͼʹ�����г�����Ϣ��������ȫ������Խ��κ������IJ���ͨ����MySQLȱ�����ݿ⣬http://bugs.mysql.com/��������Dz�������MySQL 5.1�и��������⣬���ǻὫ�����ӵ��б��С�
�ڱ��ڣ�����������MySQL 5.1��MySQL��ʵʩ�е�һЩ�仯������MySQL 5.0�����˱Ƚϡ����ǻ������۶�MySQL�صĽ�һ���ش�Ľ���Ŀǰ��ΪMySQL 5.2�滮�ġ�
��MySQL 5.0��5.1�У�NDB�ش洢����ʵʩ����֮��ı仯��Խ��٣������������Կ�ݺͼ�
ΪMySQL�ؿ�������Ҫ�����Ծ�������MySQL 5.1�����ڱ����У����ǻ��ṩ��һЩ��ʾ����������MySQL 5.1�д����Կ��ܰ����ķ��棨��μ�17.9.2�ڣ�������MySQL�ص�MySQL 5.1��չ���̡�����
MySQL 5.0.3-beta�Լ����µİ汾����һЩ��Ȥ�������ԣ�
�� ����������һ�ֲ�ѯ���磺
�� SELECT * FROM t1 WHERE non_indexed_attribute = 1;
����ʹ��ȫ��ɨ�裬�����ڴص����ݽڵ���������������ˣ�����Ҫ�������з������������ļ�¼��Ҳ����˵�����ú���������������ݴ��䣩���������ֲ�ѯ���ͣ����ٶȿ�5��10������ע�⣬ģĿǰ��������Ĭ�Ͻ�ֹ�ģ��д������IJ��ԣ�������ijЩ�����Ҳ�����ù�����ʹ�����SET engine-condition-pushdown=On; command�������ø����ԡ���Ϊ��ѡ��ʽ����Ҳ�������µġ�--engine-condition-pushdown��ѡ���־����MySQL�����������������˸����Ե�mysqld��
����ʹ��EXPLAIN���ж��ں�ʱʹ��������������
�ñ仯��һ����Ҫ�ŵ����ڣ��ܹ��Բ��з�ʽִ�в�ѯ������ζ�ţ���������ȣ��Է������еIJ�ѯҪ��5��10�����������ݽڵ����Ŀ��ԭ�����ڣ����CPU���Բ��з�ʽִ�в�ѯ��
�� ������IndexMemoryʹ�ã���MySQL 5.1�У�ÿ����¼Լ����25�ֽڵ������ڴ棬ÿ��Ψһ����ÿ��¼��ʹ��25�ֽڵ������ڴ棨����ijЩ�����ڴ棬������Ϊ���DZ����ڵ������У���������Ϊ�������ڴ��У�������Ҫ����������
�� ΪMySQL�������˲�ѯ���ٻ��壺�������ú�ʹ�ò�ѯ���ٻ���ĸ�����Ϣ����μ�5.13�ڣ���MySQL��ѯ���ٻ��塱��
�� �µ��Ż�����һ����Ҫ�����ر��ע���Ż�������Ŀǰ��ijЩ��ѯ��ʹ������ʽ��ȡ�ӿڡ����磬����������ѯ��
�� SELECT * FROM t1 WHERE primary_key IN (1,2,3,4,5,6,7,8,9,10);
��������MySQL�ذ汾��ȣ��ò�ѯ��ִ���ٶȿ�2��3����ԭ�����ڣ�ȫ��10�� ����������1�������з����ģ�������һ�η���һ����
�� ����Ԫ���ݶ������Ŀ����MySQL 4.1�У�ÿ�������ݿ������ܰ���1600��Ԫ���ݶ��������ݿ����ϵͳ����������BLOB����MySQL 5.0�У�����ϣ��������ֵ���ӵ�20320�����Ǵ�����2005�����з�����MySQL 5.0.6 beta����ʵ�ָ���ǿ���ԡ�
���������ܵ�������һ��״̬���棬����������ύ��MySQL 5.1Դ���������ݡ���ע�⣬���е�5.1�������������ʱ�仯��
Ŀǰ��������ΪMySQL 5.1��������Ҫ�����ԣ�
1. ��MySQL�ؼ��ɵ���MySQL�����У����������ܴӴ��е��κ�MySQL������ִ�и��£����ɴ��е�1��MySQL����������MySQL���ƣ��������˴ӷ������˰�װ��һ���ԡ�
2. ֧�ֻ��ڴ��̵ļ�¼����֧�ִ����ϵļ�¼�����ڰ���������ϣ�������������ֶΣ������Ա�����RAM�У������Խ����������ֶα����ڴ����ϡ�
3. ��С�ɱ�ļ�¼������ΪVARCHAR(255)����Ŀǰʹ��260�ֽڵĴ洢�ռ䣬���κ��ض���¼�б���������ء���MySQL 5.1�ر��У�ֻ���汻��¼ʵ��ռ�õ��ֶβ��֡��������ںܶ�����£��ܹ��������еĿռ�����������5����
4. �û�����ķ������ܣ��û��ܹ��������ؼ����ֶβ��ֶ��������MySQL�������ܹ������Ƿ��ܽ�ijЩ������WHERE�Ӿ���ɾ�����ܹ�����KEY��HASH��RANGE��LIST��������ִ�з����������ӷ������������ںܶ�������������ҲӦ��ʹ�ø����ԡ�
���⣬���ڴر��а�����BLOB��TEXT��������͵��У�������������8K�Ĵ�С����ֵ��������Ϊ����Ŀǰ���й̶��Ĵ�С��ҳ��СΪ32768�ֽڣ���ȥ�����б����128�ֽڣ�����Ŀǰ������ζ�ţ��������ÿ��¼ռ�õĴ�С����8K��ʣ��Ŀռ佫Ϊ�գ����14000�ֽڣ�����MySQL 5.1�У����Ǵ�����������ƣ��Ӷ�ʹ���ڸ�������ʹ��8K���ϵĿռ䲻�ᵼ��ҳʣ�ಿ�ֵ��˷ѡ�
17.10. MySQL�س���������
�� ʹ�ô���ʹ�ø��Ƶ�������ʲô��
�ڸ��������У���MySQL�������������1�������ӷ�����������˳���ύ������������ᵼ�´ӷ������ͺ�����������������ζ�ţ������������ʧ�ܣ��ӷ�������������¼����������������ʹ��������ȫ���棬��InnoDB��Ҫĩ���ڴӷ��������������Ҫĩ�Ǹ����Ͳ���¼�������Ʋ���֤���������ʹӷ������ϵ������������κ�ʱ����һ�µġ���MySQL���У����е����ݽڵ㱣��ͬ�����κ�һ�����ݽڵ��ύ�������ύ�����е����ݽڵ㡣��ijһ���ݽڵ�ʧ��ʱ������ʣ������ݽڵ����ܱ���һ�µ�״̬��
�����֮�����ܱ���MySQL�������첽�ģ���MySQL����ͬ���ġ�
���Ǽƻ���MySQL 5.1��Ϊ��ʵ�֣��첽�����ƹ��ܡ�������������֮�䣬�Լ�MySQL�غͷǴ���MySQL������֮��ĸ���������
�� Ϊ�����дأ����Ƿ���Ҫ��������������أ������еļ���������ͨ�ŵģ���
MySQL����Ϊ�ߴ��������µ�ʹ�ö���Ƶģ������ͨ��TCP/IP������������ֱ��ȡ���ڴؼ����֮��������ٶȡ����ڴأ��������Ҫ����������͵�100MB��̫��������Ч���硣������ܣ�����ʹ��GB��̫����
Ҳ֧�ָ����SCI Э�飬����Ҫ����Ӳ��������SCI�ĸ�����Ϣ����μ�17.7�ڣ���ʹ����MySQL�صĸ��ٻ�������
�� ���д���Ҫ����̨�������Ϊʲô��
Ҫ�����п��еĴأ�������Ҫ3̨�����������MySQL���У��Ƽ�����ͼ������ĿΪ4��1̨�������й����ڵ㣬1̨��������SQL�ڵ㣬2̨�����洢�ڵ㡣ʹ��2�����ݽڵ��Ŀ����Ϊ���ṩ�����ԣ������ڵ���������ڵ����Ļ����ϣ���������1�����ݽڵ�ʧ��ʱ�����ܱ�֤�������ٲ÷���
�� ���в�ͬ������������������ʲô��
MySQL�ذ������������ṹ����������������������ص������ܲ�����Ϊ�ڵ㣬���ɴؽڵ�ļ������ʱҲ��Ϊ������������������£�ÿ̨����������1���ڵ㣬���ڵ����������Ͽ����ж���ڵ㡣���������ֽڵ㣬ÿһ�ֽڵ����Ӧ�ض��Ľ�ɫ�������ǣ�
1. �����ڵ㣨MGM�ڵ㣩��Ϊ�������ṩ����������������ֹͣ�����ݡ��Լ�Ϊ�����ڵ��������ݡ������ڵ����������ΪӦ�ó���ndb_mgmdʵ�ֵģ�����ͨ��MGM�ڵ����MySQL�صĹ����ͻ�����ndb_mgm��
2. ���ݽڵ㣺����������ݡ����ݽڵ�Ĺ�����NDB���ݽڵ����ndbd��ʵ����������
3. SQL�ڵ㣺�����á�--ndb-cluster��ѡ��������MySQL��������mysqld����һ��ʵ����
�� ��ʲô����ϵͳ����ʹ�ô��أ�
��MySQL 5.1�У���Linux��Mac OS X��Solarisƽ̨�Ͼ���ʽ֧��MySQL�ء���������Ŭ��Ϊ����ƽ̨���Ӵ�֧�֣�����Windows�����ǵ�Ŀ���ǣ�������֧��MySQL����������ƽ̨��ʵ��MySQL�ء�
����������ϵͳ�����д�Ҳ�ǿ��ܵġ��û��������ǣ�������FreeBSDƽ̨�ϳ��������˴ء����ǣ�����ǰ����ܵ����ֲ���ϵͳ�⣬������ƽ̨�����еĴ�Ӧ����Ϊalpha��������������������֤�����������µĿɿ��ԣ���������MySQL AB֧����
�� ����MySQL�ص�Ӳ��Ҫ����ʲô��
�ڴ����е��κ�ƽ̨�ϣ�Ӧ���о߱�NDB���ܵĶ������ļ����Զ����������CPU������ڴ��ܹ��������ܣ�64λCPU��Ч�ʺܿ��ܸ���32λ�����������������ݽڵ�Ļ����ϱ������㹻���ڴ棬�Ա����ɸ��ڵ㹲�������ݿⲿ�֡���������Ϣ����μ�����Ҫ�����ڴ棿�����ڵ���ͨ������TCP/IP�����Ӳ������ͨ�š�����SCI֧�֣���Ҫ���������Ӳ����
�� ����MySQL��ʹ����TCP/IP�����Ƿ���ζ��������Internet������1�������ڵ�λ��Զ��λ�õĴأ�
���ס����MySQL���У��ڵ���ͨ�Ų�����ȫ����㼫����Ҫ������ͨ��δ���ܣ�Ҳδ�����κη������ơ����ڴأ��ȫ��������λ�ڷ���ǽ���ר�����磬���ܴ��ⲿֱ�ӷ����κδ����ݻ�����ڵ㣨����SQL�ڵ㣬Ӧ��ȡ��ͬ�ķ�����ʩ��������MySQL������������ʵ������������
�������κ�����������������´صĿɿ�����ʮ�����˻��ɣ�������Ϊ��ƺ�ʵʩMySQL��ʱ���ٶ����������ܱ�֤ר�ø�����ͨ�Ե������£���ʹ��100MB��GB��̫����LAN�У��������ں��ߣ������ڵ��ڸ�Ҫ����κλ���������δ���κβ��ԣ�Ҳ����֤�����ܡ�
�� Ҫ��ʹ�ôأ����Ƿò�ѧϰ�µı�����Ի��ѯ���ԣ�
��������ʹ����һЩר�����������������ôر�������������������������Ҫ����(My)SQL��ѯ�����
o ���������ĺͳ�������
o ���롢���º�ɾ�������ݡ�
o ���������ĺͳ�����������Ψһ������
o ���ú���SQL�ڵ㣨MySQL����������
�� ʹ�ô�ʱ������˽�������Ϣ�ĺ����أ�
������������ķ�ʽ��
1. ���ִ����澯״��ʱ����MySQL�������ڣ�����ʹ��SHOW ERRORS��SHOW WARNINGS��Ҳ����MySQL Query Browser����ѯ�����������ʾ���ǡ�
2. ��ϵͳshell��ʾ���£�ʹ��perror --ndb error_code��
�� MySQL��������ȫ����֧��ʲô���뼶��
����������NDB�洢���洴���ı���֧��������MySQL 5.1�У��ؽ�֧��READ_COMMITTED������뼶��
�� ��֧�ֵı�������ʲô��
NDB�ǽ��е�֧�ִع��ܵ�MySQL�洢���档
���ܹ�ʹ�������洢���������ڴص�MySQL�������ϴ���������MyISAM��InnoDB���������NDB�����ڴ�������
�� ��NDB���ĺ�����ʲô��
���ǡ�Network Database�����������ݿ⣩����д��
�� ��Щ�汾��MySQL����֧�ִأ��ұ����Դ�������
��5.1ϵ�е�����MySQL-max�����ư汾�о�֧�ִأ���������ܵij��⡣ʹ������SHOW VARIABLES LIKE 'have_%';��SHOW ENGINES;���ɼ����ķ������Ƿ�֧��NDB��������Ϣ����μ�5.1.2�ڣ���mysqld-max��չMySQL������������
Linux�û���ע�⣬NDBδ����������MySQL������RPM�С�����NDB�洢�����Լ������Ĺ������ߺ��������ߣ��е�����RPM����������μ�MySQL 5.1����ҳ�ϵ�NDB RPM���ز��֣���ǰ�������ʹ����.tar.gz������ʽ�ṩ����-max���������ļ���Ŀǰ������������ȴ���DZ���ģ����Ը�⣬��ʹ��Linux�ַ����RPM����������ͨ����Դ�����-max�������ļ���Ҳ�ܻ��NDB֧�֣���ʹ��MySQL��ʱ������Ҫ������Ҫ��ֻ�������µ�MySQL 5.1ϵ�еĶ����ư汾��RPM����Դ��ַ��棬�����http://dev.mysql.com/downloads/mysql/5.1.html��
�� ����Ҫ����RAM���Ƿ���ȫ��ʹ�ô����ڴ棿
��Ŀǰ�����ǽ����ڴ��С��ġ�����ζ�����еı����ݣ�������������������RAM�С���ˣ�����������ռ����1GB�Ŀռ䣬���Ҵ����ڴ��н�������1�Σ���Ҫ2GB���ڴ档��Ӧ���ϲ���ϵͳ�Լ��ڴؼ���������е�Ӧ�ó���������ڴ档
����ʹ��������˾���Թ��ƴ���ÿ�����ݽڵ������RAM����
(SizeofDatabase * NumberOfReplicas * 1.1 ) / NumberOfDataNodes
Ҫ���ȷ�ؼ����ڴ�����������ҪΪ�����ݿ��е�ÿ����ȷ��ÿ������Ĵ洢�ռ䣨������μ�11.5�ڣ��������ʹ洢��������Ȼ�����ռ����������������������м��㣬��ʽ���£�
o ����ΪNDB�ر�������ÿ�������������ϣ������ÿ��¼��Ҫ21-25�ֽڡ���������ʹ��IndexMemory�������ڴ棩��
o ÿ����������ÿ��¼��Ҫ10�ֽڵĴ洢�ռ䣬ʹ��DataMemory�������ڴ棩��
o ����������Ψһ����ʱ�����ᴴ��1���������������Ǹ�������ʹ��USING HASH�����ġ����仰�������δʹ��USING HASH�������ǣ������ر��ϵ�ÿ���������Ψһ��������MySQL 5.1�У�ÿ��¼ռ��31-35�ֽڡ�
ע�⣬ʹ��USING HASHΪ����������Ψһ��������MySQL�ر�ʱ��ͨ������ʹ���ĸ����ٶȸ��졣������Ϊ������Ҫ���ٵ��ڴ棨��δ������������������CPU��ռ��Ҳ�ϵͣ������ȡ����½��ٵ���������
���ס�����е�MySQL�ر���������������㼫����Ҫ�����δ���壬NDB�洢���潫�Զ��������������Ҹ���������δʹ��USING HASH�������´����ġ�
����ȷȷ�����������κθ���ʱ�����ڴ洢���ڴ��������ǣ�������DataMemory��/��IndexMemory��ʹ���ʵ���80��ʱ���Ὣ������Ϣд�����־������80����90����ʱ��Ҳ��д�����־��
���Ǿ��������û�ͨ�����������⣬��������ͼ�������ݿ�ʱ�����ؽ�����ǰ��ֹ������ʾ����������Ϣ��
����1114����'my_cluster_table'������
���ָ����ʱ���ܿ�������Ϊ�����������δΪ���еı����ݺ������ṩ�㹻��RAM������NDB�洢����������������Լ��������в�������������ʱ�Զ�������������
���Ӧע�⣬���е����ݽڵ�Ӧ������ͬ��RAM����������Ϊ�������κ����ݽڵ�����ʹ�õ��ڴ�����������ⵥ�����ݽڵ����Ϳ����ڴ档���仰�����������̨���д����ݽڵ�ļ��������������̨������ϣ���3GB���ڱ�������ݵ�RAM����һ̨�����ֻ��1GB RAM����ôÿ�����ݽڵ����Ϊ�ع���1GB��
�� ���������Թ���ʱ�������������жϵ�����ҵ�UPSҲ���ֹ��ϣ��һᶪʧ���е�������
�������ύ��������¼����ˣ��ڳ������ѵ�����£�ijЩ���ݿ��ܻᶪʧ�����൱���ޡ�ͨ������ÿ����IJ��������ܹ���һ������������ʧ�����κ������£���ÿ������ִ�д�������������һ�������⣩��
�� �ܹ����һ��ʹ��FULLTEXT������
FULLTEXT��������Ŀǰ����NDB�洢����֧�֣�Ҳ������MyISAM֮����κδ洢����֧�֡����Ǵ�����δ���İ汾�����Ӹù��ܡ�
�� ������һ̨����������ж���ڵ���
���ԣ������������������дص���Ҫԭ��֮һ���ṩ���࣬Ϊ�˻�������Ե�ȫ���ŵ㣬ÿ���ڵ�Ӧλ�ڵ����ļ�����ϡ����������ڵ�����ͬһ̨���������û������ֹ���ʱ�����нڵ������ʧ�����ǵ�MySQL���������ڳ�����Ӳ���ϲ��������۵IJ���ϵͳ��������ã���Ϊ��ȷ������ؼ������ݵİ�ȫ��ֵ��Ϊ����Ļ��������ѿ����������ע�⣬�����й����ڵ�Ĵ�������Ҫ����ͣ�ʹ��200 MHz Pentium CPU������ϵͳ������㹻RAM���Լ�����ndb_mgmd��ndb_mgm���̵�����������������ɸ�����
�� �����ڲ������������Ϊ�����ӽڵ���
Ŀǰ���С������ڴ��������µ�MGM��SQL�ڵ���˵�����������������һ�С��������ݽڵ�ʱ������������Щ����Ҫ��ȡ�������裺
o �����д����ݽ����������ݡ�
o ���رմغ����еĴؽڵ���̡�
o ʹ�á���initial������ѡ�������ء�
o �ӱ����лָ����д����ݡ�
��δ����MySQL�ذ汾�У�����ϣ��ΪMySQL��ʵ�֡��ȡ������ù��ܣ��Ա��ܹ��������½ڵ�ʱ�����ص�Ҫ������ͣ�������������Ļ�����
�� ʹ�ô�ʱ����Ҫ���˽��������
MySQL�е�NDB�������������ƣ�
o �������е��ַ�����У�Ծ���֧�֡�
o ��֧��FULLTEXT������ǰ������ֻ��Ϊ��������������������֧����19�£�MySQL�еĿռ���չ�н��ܵĿռ���չ��
o ��֧�ֶ�����������ع�����֧�ֲ��ֻع��Լ��ع�������㡣
o ÿ�����������������Ϊ128�������������Ʋ��ó���31���ַ�������ÿ�������������ݿ����Ƶ������ϳ���Ϊ122���ַ���
o ���е�����СΪ8KB��������BLOB������ÿ���е�����û�����ƣ����Ĵ�С����ȡ���ڶ������أ�������ÿ�����ݽڵ���õ�RAM����
o NDB������֧�����Լ��������MyISAM��һ������ЩԼ���������ԡ�
o ��֧�ֲ�ѯ���ٻ��幦�ܡ�
���ڴ����Ƶĸ�����Ϣ����μ�17.8�ڣ���MySQL�ص���֪���ơ���
�� ���������е�MySQL���ݿ�뵽���У�
���Խ����ݿ�뵽MySQL���У������������汾��MySQL����������ǰһ�������ᵽ�������⣬���е�����Ҫ���ǣ������������е��κα�����ʹ��NDB�洢���档����ζ�ţ�����������ENGINE=NDB��ENGINE=NDBCLUSTER�����ġ�ʹ��ALTER TABLE���ܹ���ʹ�������洢��������б�ת��ΪNDB�ر�������Ҫ��ȡ����ܹ��ʩ��������μ�17.8�ڣ���MySQL�ص���֪���ơ���
�� �ؽڵ��������˴�ͨ�ŵģ�
�ؽڵ��ܹ�ͨ����������Э���е��κ�һ�ֽ���ͨ�ţ�TCP/IP��SHM�������ڴ棩��SCI����ģ����չ�ļ�������ӽӿڣ��������õij��ϣ�����λ����ͬ�������ϵĽڵ��ͨ�ţ�Ĭ��Э��ΪSHM��SCI�Ǹ��٣�ÿ��1GB����ߣ����߿�����Э�飬���ڴ�������չ�Ķദ����ϵͳ������Ҫ����Ӳ��������������ʹ��SCI��Ϊ���д�����Ƶĸ�����Ϣ����μ�17.7�ڣ���ʹ����MySQL�صĸ��ٻ�������
�� ʲô�ǡ�arbitrator�����ٲó�����
������е�1�������ڵ�ʧ�ܣ��������еĴؽڵ�����ܱ˴ˡ������������ǿ��ܵġ���ʵ�ϣ��ܹ�����������н������ڵ㼯�ϱ˴˸��룬Ҳ��Ϊ�����Ѵ��ԡ����������β����ܻ�ӭ��������Ϊ��ÿһ���ڵ㼯�϶���ͼ����Ϊ���������ء�
���ؽڵ��������ʱ�������ֿ����ԡ����ʣ��ڵ��50�������ܹ��˴�ͨ�ţ���ô�����������ʱ��֮Ϊ�ġ�����֧�䡱���Σ��ýڵ㼯�Ͻ�����Ϊ�ء����ڵ�������ʱ���ٲó����룺�ڸ������£��ٲó��������Ľڵ㼯�Ͻ��������أ������ڸýڵ㼯�ϵĽڵ㽫���رա�
����������Ϊ���������Ľ�����Ҫ����������ܵĽڵ��飺
������һ���ڵ����е����нڵ����Чʱ����������������⣬������Ϊ�����е���һ�����־����ܹ���1�������ԵĴء���û��һ���ڵ�������г�Ա������Ч��ʱ������������ڸ�����£���������������Ѵ��ԡ����Σ���Ϊ���ܡ�������Ҫ�ٲó������еĴؽڵ㽫��ͬ�Ľڵ���Ϊ�ٲó���ͨ���ǹ��������������ǣ�Ҳ�ܽ����е��κ�MySQL����������Ϊ�ٲó����ٲó�����ܵ�һ������Ӵ��Ĵؽڵ㼯�ϣ���֪ͨʣ��ļ��Ϲرա�����MySQL�����������������ڵ㣬�ٲó����ѡ������ArbitrationRank���ò������Ƶ���������μ�17.4.4.4�ڣ�������MySQL�ع������������������Ӧע�⣬�ٲó����ָ������ʩ�ӹ����Ҫ����ˣ��ٲó�����������Ҫ�ر���ӵ�����ڸ�Ŀ�ĵĶ����ڴ档
�� MySQL��֧�ֵ���������ʲô��
MySQL��֧������ͨ����MySQL�����ͣ�����MySQL�ռ���չ�йص����⣨��μ���19�£�MySQL�еĿռ���չ�������⣬��������������NDB��һ��ʹ��ʱ����һЩ���ע�ͣ�MySQL�ر�������ENGINE=NDBCLUSTER�����ı������й̶������С�����ζ�ţ����磩����VARCHAR(255)�е�ÿһ����¼��Ҫ256�ֽ��������У��������б�������ݴ�С�Ƕ��١���δ����MySQL�汾�У��ƻ���������
������Щ����ĸ�����Ϣ����μ�17.8�ڣ���MySQL�ص���֪���ơ���
�� ���������ֹͣMySQL�أ�
��Ҫ��������˳��ֱ��������е�ÿ���ڵ㣺
1. ��ndb_mgmd�������������ڵ㡣
2. ��ndbd��������ÿ�����ݽڵ㡣
3. ʹ��mysqld_safe --user=mysql &������ÿ��MySQL��������SQL�ڵ㣩��
�������������е�ÿһ������������Ӱ��ڵ����ڻ����ϵ�ϵͳshell��ִ�С�������MGM�ڵ�Ļ��������������ͻ���ndb_mgm������֤���Ƿ��������С�
�� ���عر�ʱ����Դ�������ʲôӰ�죿
�ɴ����ݽڵ㱣�����ڴ��е����ݽ���д����̣�������һ��������ʱ����װ���ڴ档
Ҫ��رմأ�����MGM�ڵ����ڵĻ����ϡ���shell�������������
shell> ndb_mgm -e shutdown
��������ǡ������ֹndb_mgm��ndb_mgm���Լ��κ�ndbd���̡�����������SQL�ڵ��MySQL����������ʹ��mysqladmin shutdownֹͣ����
������Ϣ����μ�17.6.2�ڣ��������ͻ��ˡ��е�������17.3.6�ڣ�����ȫ�رպ���������
�� ������1�����ϵĹ����ڵ��Ƿ����ã�
���ڿɿ�����˵��ȷ�а��������κθ�����ʱ�䣬����1��MGM�ڵ������ƴأ����ܹ���1��MGM����Ϊ���ڵ㣬������1����������Ĺ����ڵ㣬�Ա�����MGM�ڵ���ֹ���ʱȡ������
�� �ڴ����ܻ��ʹ�ò�ͬ��Ӳ���Ͳ���ϵͳ��
�ǡ�ֻҪ���еĻ����Ͳ���ϵͳ������ͬ��endian��Ҳ���ڲ�ͬ�Ľڵ���ʹ�ò�ͬ��MySQL�ذ汾�����ǣ����ǽ����Ӧ������Ϊ����������һ����ʹ�á�
�� �����ڵ�̨�����������������ݽڵ�������SQL�ڵ㣿
�ǣ��ܹ����������ж�����ݽڵ������£�ÿ���ڵ����ʹ�ò�ͬ������Ŀ¼�����������һ̨���������ж��SQL�ڵ㣬��ôÿ��mysqldʵ������ʹ�ò�ͬ��TCP/IP�˿ڡ�
�� ������MySQL��һ��ʹ����������
�ǣ����ڴ��������ܹ�ʹ��DNS��DHCP�����ǣ�������Ӧ�ó���Ҫ��99.999�����Ŀ����ԣ�����ʹ�ù̶���IP��ַ��������Ϊ�������÷���Ĵؽڵ���ͨ�Ż��������Ĺ��ϵ㣬���ϵ�Խ��Խ�á�
������������������MySQL��������������������MySQL��һ��ʹ��ʱ��һ�������⺬�塣
�� �أ�
����ͨ�������⣬����һ����������ϣ��书���൱��1����λ��һ��������ɵ�һ����
NDB�أ�
����MySQL��ʹ�õĴ洢���棬����ʵ�����ݴ洢���������Լ�����������ֲ�ʽ������
MySQL�أ�
ָ����ʹ��NDB�洢����һ������һ���������Ա���ʹ�á��ڴ��С��洢�ķǹ�����ϵ�ṹ��֧�ֲַ�ʽMySQL���ݿ⡣
�� �����ļ���
������ء��������ͽڵ��йص�ָ�����Ϣ���ı��ļ�����������ʱ�������ļ��ɴصĹ����ڵ㸺���ȡ��������μ�17.4.4�ڣ��������ļ�����
�� ���ݣ�
���д����ݡ��������־�����������������ڴ����ϻ��������ڴ洢�����ϡ�
�� �ָ���
���ط�����ǰ��״̬���뱣���ڱ����е���ͬ��
�� ���㣺
�ӹ����Ͻ��������ݱ��浽����ʱ�����ﵽ�˼��㡣������ڴ���˵�����ǽ��������ύ���浽���̵�ʱ��㡣����NDB�洢���棬������һ�����ļ��㣬��ȷ��ά�������ݵ�һ���ԣ�
o ���ؼ��㣨LCP����
����ר����Ե�һ�ڵ�ļ��㣬���ǣ�LCPҲ���ڴ��е����нڵ㷢����ͬ���Ի�ǿ������LCP�������ڵ���������ݱ��浽���̣�ͨ��ÿ�����ӳ���һ�Ρ�ȷ��ʱ��������ֱ仯���������ȡ���ڽڵ��ϱ�������������ػ�ļ����Լ��������ء�
o ȫ�ּ��㣨GCP����
GCPÿ�������һ�Σ���ʱ���������нڵ���������ͬ��������������redo��־���浽���̡�
�� ��������
����MySQL����ɲ��ֵļ�������ؾ��������ṹ�����ṹ�������������Ͻ������ɶ����������ɣ���Щ�����Ҳ��Ϊ��������������������μ�������ڵ����ڵ�����
�� �ڵ㣺
��ָ����MySQL�ص��������Ե�Ԫ����ʱҲ��Ϊ�ؽڵ㡣����MySQL�أ�����ʹ������ڵ㡱��ʾ���̶����Ǵص�����������ʵʩ��Ч��MySQL����Ҫ���ֽڵ㡣�����ǣ�
o ������MGM���ڵ㣺
����������е������ڵ㡣��Ϊ�����ڵ��ṩ���������ݣ�����������ֹͣ�ڵ㣬��������������ˣ��������ݺʹӱ��ݻָ����ȵȡ�
o SQL��MySQL���������ڵ㣺
MySQL��������ʵ�������������ݽڵ����������ݵ�ǰ�ˡ����㱣�桢������������ݵĿͻ��˿ɷ���SQL�ڵ㣬�����������MySQL������һ��������ͨ���ļ���������API���ڵ���֮��Ļ������ݷ�����û���Ӧ�ó�����˵�����ġ�SQL�ڵ������Ϊ����Ĵ����ݿ⣬�����������ڲ�ͬ���ݽڵ��������ϵķֲ������
o ���ݽڵ㣺
��Щ�ڵ㸺�𱣴�ʵ�����ݡ�������Ƭ�α����ڽڵ��鼯���У�ÿ���ڵ��鱣������ݵIJ�ͬ�Ӽ������ɽڵ����ÿ���ڵ�������˸ýڵ���������Ƭ�εĸ�����Ŀǰ��1������֧������Ϊ48�����ݽڵ㡣
1�����ϵĽڵ��ܹ����ڵ�̨�����ϣ���ʵ�ϣ��ܹ���һ̨������������ɵĴأ��������������¼���û�˻��������������ס��ʹ��MySQL��ʱ�����������ָ���Ǵص����������������ڵ㡱ָ���������ܲ����������̣�������а�����
���ڹ�ʱ�����ע�ͣ���MySQL���ĵ������ڰ汾�У����ݽڵ���ʱҲ��Ϊ�����ݿ�ڵ㡱����DB�ڵ�������ż��ʹ�õġ��洢�ڵ��������⣬SQL�ڵ���ʱҲ��Ϊ���ͻ��˽ڵ㡱��API�ڵ㡱��Ϊ�˽�����������ͣ��������������ѱ�������Ϊ�ˣ�Ӧ����ʹ�����ǡ�
�� �ڵ��飺
���ݽڵ�ļ��ϡ�λ�ڽڵ����ڵ��������ݽڵ������ͬ�����ݣ�Ƭ�Σ������ҵ������ڵ����нڵ�Ӧλ�ڲ�ͬ�������ϡ��ܹ����ĸ��ڵ������ĸ��ڵ�����п��ơ�
�� �ڵ�ʧ�ܣ�
MySQL�ز�����ȡ���ڹ��ɹ��ɴص���һ�ڵ�Ĺ��ܣ����1�������ڵ�ʧ�ܣ����������С������������̵�ʧ�ܽڵ��ȷ��Ŀȡ���ڽڵ����Ŀ�ʹص����á�
�� �ڵ�������
����ʧ�ܴؽڵ�Ľ��̡�
�� �״νڵ�������
�������ļ�ϵͳһ�������ؽڵ�Ľ��̡���ʱ���������������������ⳡ�ϡ�
�� ϵͳ��������ϵͳʧ�ܣ���
���ܶ�ؽڵ�ʧ�ܲ�����֤�ص�״̬ʱ���ͻ���ָ������
�� ϵͳ������
�����ز����ݴ�����־�ͼ������³�ʼ����״̬�Ľ��̡��ڴصļƻ��رջ�Ǽƻ��رպ�ͨ����Ҫִ�иý��̡�
�� Ƭ�Σ�
���ݿ����һ���֣���NDB�洢�����У�������Ϊ�ڶ�Ƭ�Σ�����Ƭ�η�ʽ���档Ƭ����ʱҲ��Ϊ��������������Ƭ�Ρ��Ǹ���ȡ�������MySQL���У��Ա�������Ƭ�λ��������Ӷ����˻����ͽڵ��ĸ���ƽ�⡣
�� ������
��NDB�洢�����£�ÿ����Ƭ�ξ��ж����������Щ�����������������ݽڵ��ϣ����ṩ�����ԡ�Ŀǰ��ÿƬ�������4��������
�� ��������
�ṩ�ڵ�����ݴ����Э�顣MySQL��Ŀǰ�ṩ�����ֲ�ͬ�Ĵ��������ӣ�
o TCP/IP�����أ�
��Ȼ�����ǹ�Ϊ��֪������Э�飬����Internet��HTTP��FTP�ȵĻ�����
o TCP/IP��Զ�̣�
ͬ�ϣ�������Զ��ͨ�š�
o SCI
SCI����ģ����չ�ļ�������ӽӿڣ���һ�ָ���Э�飬���ڹ����ദ����ϵͳ�Ͳ��д���Ӧ�ó�����MySQL��һ��ʹ��SCIʱ����Ҫר�ŵ�Ӳ��������������μ�17.7.1�ڣ�������MySQL����ʹ��SCI���֡�������SCI�Ļ������ܣ���μ�dolphinics.com�ϵ����¡�
o SHM
Unix������ڴ棨SHM���Ρ����κ�֧�ֵij����£����Զ�ʹ��SHM��������������ͬ�����ϵĽڵ㡣Ҫ���˽��ⷽ��ĸ�����Ϣ����μ�����shmop(2)��Unix�ֲ�ҳ��
ע�ͣ��ش������Ǵ��ڲ��ġ�ʹ��MySQL�ص�Ӧ�ó�����SQL�ڵ����ͨ�ţ������������汾��MySQL����������ͨ��һ����ͨ��TCP/IP����ʹ��Unix���֡���Windows�����ܵ���������ʹ�ñ���MySQL API������ѯ�����������
�� NDB��
�����������ݿ⣨Network Database������д������ָ������������MySQL�صĴ洢���档NDB�洢����֧������ͨ����MySQL�����ͺ�SQL��䣬������ACID���ݵġ������滹�ṩ�˶����������֧�֣��ύ�ͻع�����
�� ������ϵ�ṹ��
����MySQL�ص�������ϵ�ṹ�������������������£�ÿ���ڵ������ڵ����������ϡ����ల�ŵ��ŵ����ڣ�����������ڵ㲻����ɵ�����ϣ�Ҳ�����Ϊϵͳ���������ƿ����
�� �ڴ��д洢��
������ÿ�����ݽڵ��е����ݾ������ڽڵ�������������ڴ��С����ڴ��е�ÿ�����ݽڵ㣬�����ṩ�㹻��RAM�������RAM��Ϊ�����ݿ�Ĵ�С���Ը�����Ŀ��Ȼ��������ݽڵ����Ŀ����ˣ�������ݿ�ռ��1GB���ڴ棬������������þ���4��������8�����ݽڵ�Ĵأ�ÿ�ڵ��������С�ڴ�Ϊ500 MB��ע�⣬��Ӧ���ϲ���ϵͳ������ڴ��Լ������������ϵ�Ӧ�ó���������ڴ档
�� ����
��������ݿ��µ�ͨ�����һ�����������ָ���Ǿ��е�ͬ�ṹ�ļ�¼�ļ��ϡ���MySQL���У����ݿ����Ƭ�μ��ϵķ�ʽ���������ݽڵ��У�����ÿ��Ƭ�θ��Ƶ���������ݽڵ��ϡ�������ͬƬ�λ�Ƭ�μ��ϵ����ݽڵ㼯�ϳ�Ϊ�ڵ��顣
�� �س���
�����������г����������С����ú���MySQL�ء����ǰ������ַ������˿ڼල����
o ndbd:
���ݽڵ�˿ڼල�����������ݽڵ���̣���
o ndb_mgmd:
�����������˿ڼල�������й������������̣���
�Լ��ͻ��˳���
o ndb_mgm:
�����ͻ��ˣ�Ϊִ�й��������ṩ��1�����棩��
o ndb_waiter:
������֤�������нڵ��״̬��
o ndb_restore:
�ӱ����лָ������ݡ�
������Щ�������÷��ĸ�����Ϣ����μ�17.5�ڣ���MySQL���еĽ��̹�������
�� �¼���־��
MySQL�ذ������������ֹͣ��������ȣ������ȼ������ؼ�������¼�¼����������п�ͨ���¼��������б�����μ�17.6.3�ڣ���MySQL�������ɵ��¼����桱���¼���־�����������ͣ�
o ����־��
Ϊ��Ϊ����Ĵؼ�¼��������ġ�ֵ�ü�¼���¼���
o �ڵ���־��
Ϊÿ�������ڵ㱣��ĵ�����־��
����������£����豣��ͼ�����־����ͨ�����㹻���ڵ���־������Ӧ�ó����͵���Ŀ�ġ�